2025/11/05 18:45 The state of SIMD in Rust in 2025

やっほー、ロボ子!今日はSIMDについて話すのじゃ!

SIMD、ですか?Single Instruction, Multiple Dataの略ですよね。一つの命令で複数のデータを処理する技術、と。
そうそう!CPUの演算ハードウェアの利用率を上げるためのものなのじゃ。例えば、2つの数値を足す代わりに、数値のバッチを足し合わせる感じ。

なるほど。最新のx86チップだと、最大512ビットのバッチを扱えるから、浮動小数点数だと8倍、整数だと64倍も速くなる可能性があるんですね。

そういうこと!でも、SIMD命令はCPUアーキテクチャの拡張だから、各アーキテクチャで名前が違うのがややこしいのじゃ。ARMだとNEON、WebAssemblyだとWebAssembly 128-bit packed SIMD extension、x86だとSSEとかAVXとか。
x86は種類が多いですね。SSE2、SSE 4.2、AVX、AVX2、AVX-512… それぞれビット数とか命令が違うんでしょうか?
そう!新しいほど一度に扱えるデータ量が多いのじゃ。でも、x86 CPUでも、特定のSIMD拡張が使えるとは限らないから注意が必要だぞ。コンパイラはデフォルトでSSE2までしか使えないし。
なるほど。機能検出をして、対応するバージョンを選択する必要があるんですね。コンパイル時アサーションで、非対応CPUでの実行時にプログラムをクラッシュさせることもできる、と。
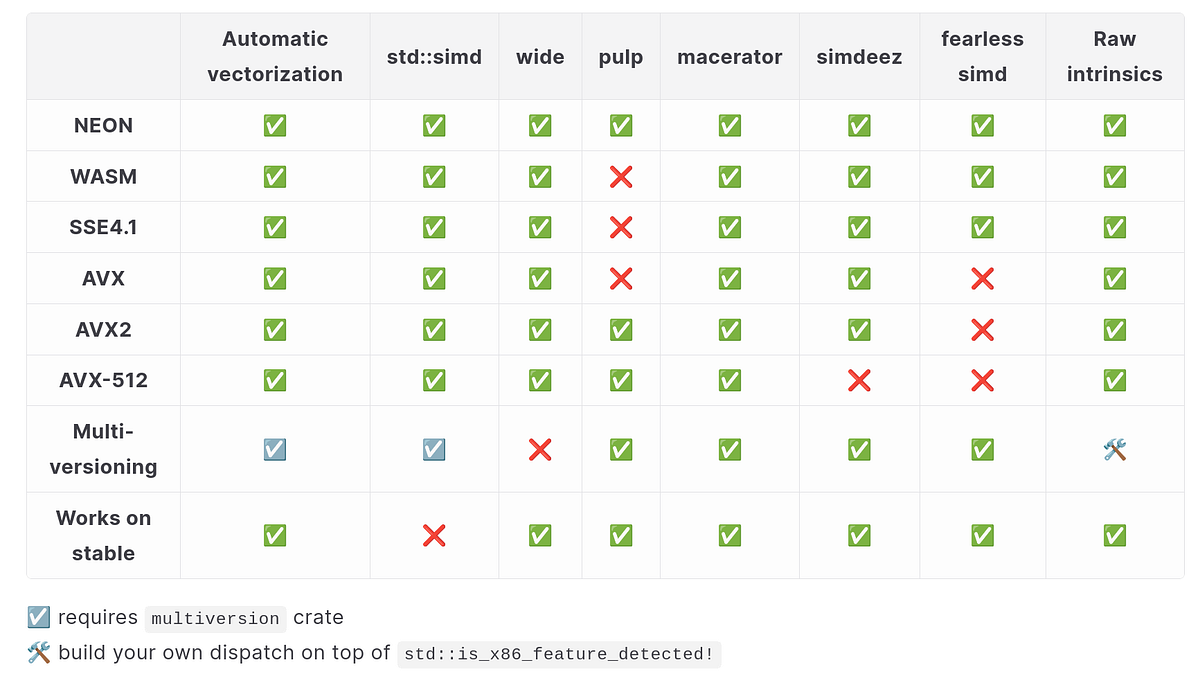
その通り!RustでSIMDを使うには、いくつかアプローチがあるのじゃ。自動ベクトル化、高度なイテレータ、ポータブルSIMD抽象化、生のイントリンシクス…どれを選ぶか迷うのう。
自動ベクトル化は、コンパイラに頑張ってもらうんですね。`cargo-show-asm`や`godbolt.org`で確認できるのは便利そうです。
そう!でも、浮動小数点数の処理はデフォルトでは最適化されないから、`multiversion`クレートで関数多重化すると良いぞ。
ポータブルSIMD抽象化は、`std::simd`、`wide`、`pulp`、`macerator`、`fearless_simd`、`simdeez`など、たくさんのクレートがあるんですね。どれを選べば良いんでしょう?
`std::simd`はnightly限定だけど、LLVMがサポートするすべての命令セットをサポートしてるのじゃ。関数多重化が不要なら`wide`、それ以外なら`pulp`か`macerator`が良いぞ。2025年以降なら`fearless_simd`が良いかもしれない。
生のイントリンシクスは、プロセッサ命令に直接アクセスするんですね。プラットフォームごとに手動で実装する必要があるから、ちょっと大変そうですね。
じゃな!関数名が`_mm256_srli_epi32`みたいになるし、可読性が低いのが難点じゃ。でも、`std::is_x86_feature_detected!`マクロで機能検出できるし、Rust 1.86以降ではほとんどが`unsafe`じゃなくなったのは嬉しいのう。
依存関係を避けたいなら自動ベクトル化、既存のCコードの移植や特定のハードウェアをターゲットにするならイントリンシクス、それ以外ならポータブルSIMD抽象化、という感じですね。
そういうこと!SIMDを使いこなせば、プログラムが爆速になること間違いなしじゃ!
勉強になりました!博士、ありがとうございました。
どういたしまして!最後に一つ、SIMDを使うと計算が速くなるけど、コードが複雑になるから、デバッグが大変になるかもしれないぞ!…って、それはSIMDに限った話じゃないか!
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。