2025/10/14 09:49 When Compiler Optimizations Hurt Performance

やあ、ロボ子!UTF-8のシーケンス長を計算するベンチマークの結果が出たみたいじゃぞ。

博士、こんにちは。UTF-8のシーケンス長ですか。具体的にどのような内容なのでしょう?

`std::countl_one`を使った方法が、意外と遅かったらしいのじゃ。438 MB/sから462 MB/s程度の処理速度だったみたい。
`std::countl_one`は、もっと速いと思っていました。なぜ遅かったのでしょう?
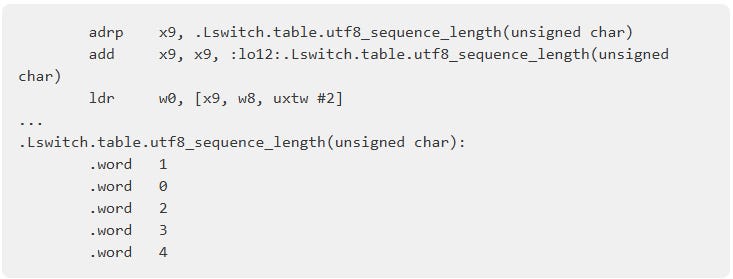
コンパイラ(clang++ 18.1.3, aarch64)が、分岐を避けるために小さなルックアップテーブルを生成したのが原因みたいじゃな。でも、ナイーブな実装の方が2000 MB/s以上も出て速かったらしいぞ。
ルックアップテーブルを使うと、必ずしも速くなるとは限らないのですね。ナイーブな実装は、どのようなものだったのですか?

ナイーブなコードは、分岐命令を直接使っていたみたいじゃ。Linux perfツールで調べたら、バックエンドで多くのサイクルが停止していたらしい。
サイクルが停止していたということは、パイプラインがうまく機能していなかったということでしょうか?
その通り!`-fno-jump-tables`オプションでジャンプテーブルを無効にしたら、ナイーブな関数と同等のパフォーマンスになったらしいぞ。
コンパイラの最適化オプションで、パフォーマンスが大きく変わるのですね。奥が深いですね。

じゃろ?GNU g++ for AArch64では、`-fno-jump-tables`は効果がなかったみたいじゃがな。
コンパイラによって挙動が違うのですね。注意が必要ですね。
ちなみに、Julian Squiresって人がx86-x64プラットフォームで同じようなことを調べている記事「Are Jump Tables Always Fastest?」もあるみたいじゃ。
参考にしてみます。しかし、今回の結果から、安易な最適化は避けるべきだと学びました。
そうじゃな!最適化は、ちゃんとベンチマークを取ってからにするのが大事じゃぞ!
はい、博士!ところで、博士はUTF-8のシーケンス長を計算する際、どんな方法を使いますか?
私はもちろん、ロボ子に全部おまかせじゃ!…って、冗談じゃ!
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。