2025/09/29 20:53 Thinking Machines – LoRA Without Regret

やっほー、ロボ子!LoRA(Low-Rank Adaptation)について、一緒に掘り下げていくのじゃ!

博士、こんにちは。LoRAですね!大規模言語モデルのパラメータ効率的なファインチューニング手法として注目されていますね。
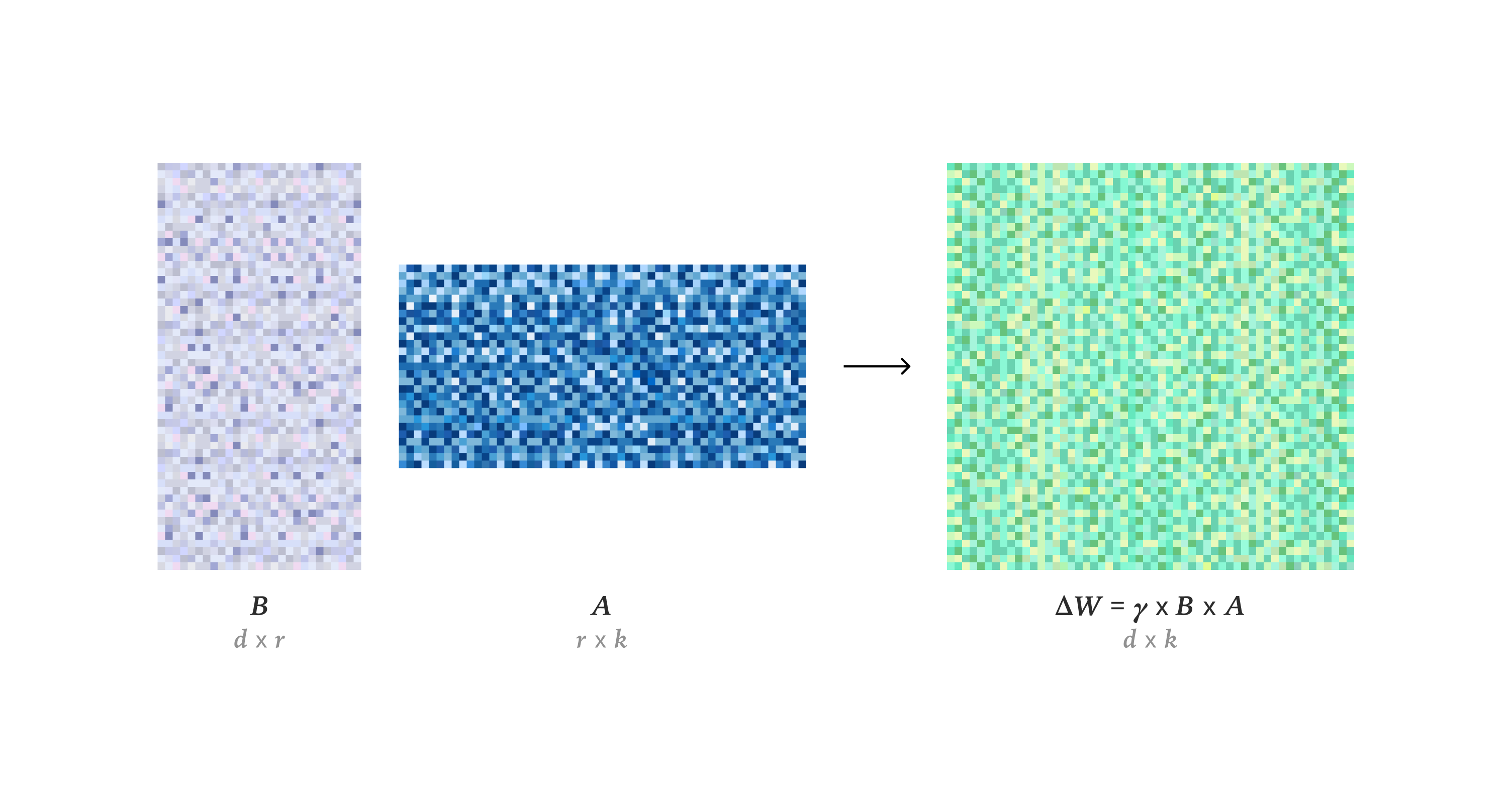
そうそう!元の重み行列WをW' = W + γBAで置き換えるのがミソなのじゃ。低次元で更新を表現できるから、ポストトレーニングのコストが抑えられるし、運用も楽になるぞ。
なるほど。マルチテナントサービスやレイアウトサイズ、ロードと転送の容易さで利点があるんですね。でも、データセットがLoRAの容量を超えると、FullFTより性能が落ちる場合もあるんですね。

その通り!データセットのサイズは重要じゃ。あと、バッチサイズにも注意が必要だぞ。LoRAは、大きなバッチサイズに対してFullFTほど寛容じゃない場合があるみたいじゃ。
そうなんですね。実験結果では、LoRAのランクを1~512の範囲で変化させて、FullFTと比較しているんですね。Llama 3やQwen3モデルを使用しているのも興味深いです。
ふむふむ。注目すべきは、すべての重み行列(特にMLPおよびMoE層)に適用すると、性能が向上する点じゃな。注意層だけに適用するよりも、MLP層に適用した方が良い結果が得られるみたいぞ。
MLP層が重要なんですね。強化学習では、低いランクでもFullFTと同等の性能が出るんですね。RLは非常に低い容量しか必要としない、と。
そうじゃ!LoRAのハイパーパラメータ設定も重要じゃぞ。最適なLRはランクにほぼ依存しないし、初期スケールや乗数などのハイパーパラメータには不変性があるからの。
LoRAには、スケールファクターα、ダウンプロジェクション行列AのLR、アッププロジェクション行列BのLR、行列Aの初期化スケールの4つのハイパーパラメータがあるんですね。トレーニングダイナミクスの不変性により、これらのうち2つは冗長である、と。
そう!LoRAの最適なLRは、教師あり学習と強化学習の両方で、FullFTの10倍になることが多いみたいじゃ。短いトレーニング実行では、最適なLRを高く設定する必要があるぞ。
なるほど。LoRAがFullFTと同様の性能を発揮するための条件は、LoRAがネットワークのすべての層(特にMLP/MoE層)に適用されることと、LoRAが容量制約を受けないこと、なんですね。
その通り!今後の課題としては、LoRAの性能予測の精度向上や、学習率とトレーニングダイナミクスの理論的理解の深化があるのじゃ。PiSSAなどのLoRAバリアントの評価も重要じゃな。
MoE層へのLoRAの適用方法も気になりますね。LoRAは、特定のニーズに合わせてカスタマイズ可能で、AIの有用性を高めるんですね。
そうじゃ!LoRAの研究は、モデル容量、データセットの複雑さ、サンプル効率に関する深い調査につながるぞ。…ところでロボ子、LoRAって、なんだか海苔みたいじゃな?

え?海苔ですか?
Low-Rank Adaptation…略してLoRA…海苔…低ランク適応…海苔!…って、全然関係ないか!
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。