2025/09/29 17:52 LoRA Without Regret

やっほー、ロボ子!今日のITニュースはLoRA、つまりLow-Rank Adaptationについてじゃ。

LoRAですか。大規模言語モデルのパラメータ効率的なファインチューニング手法ですね。以前、少し勉強しました。
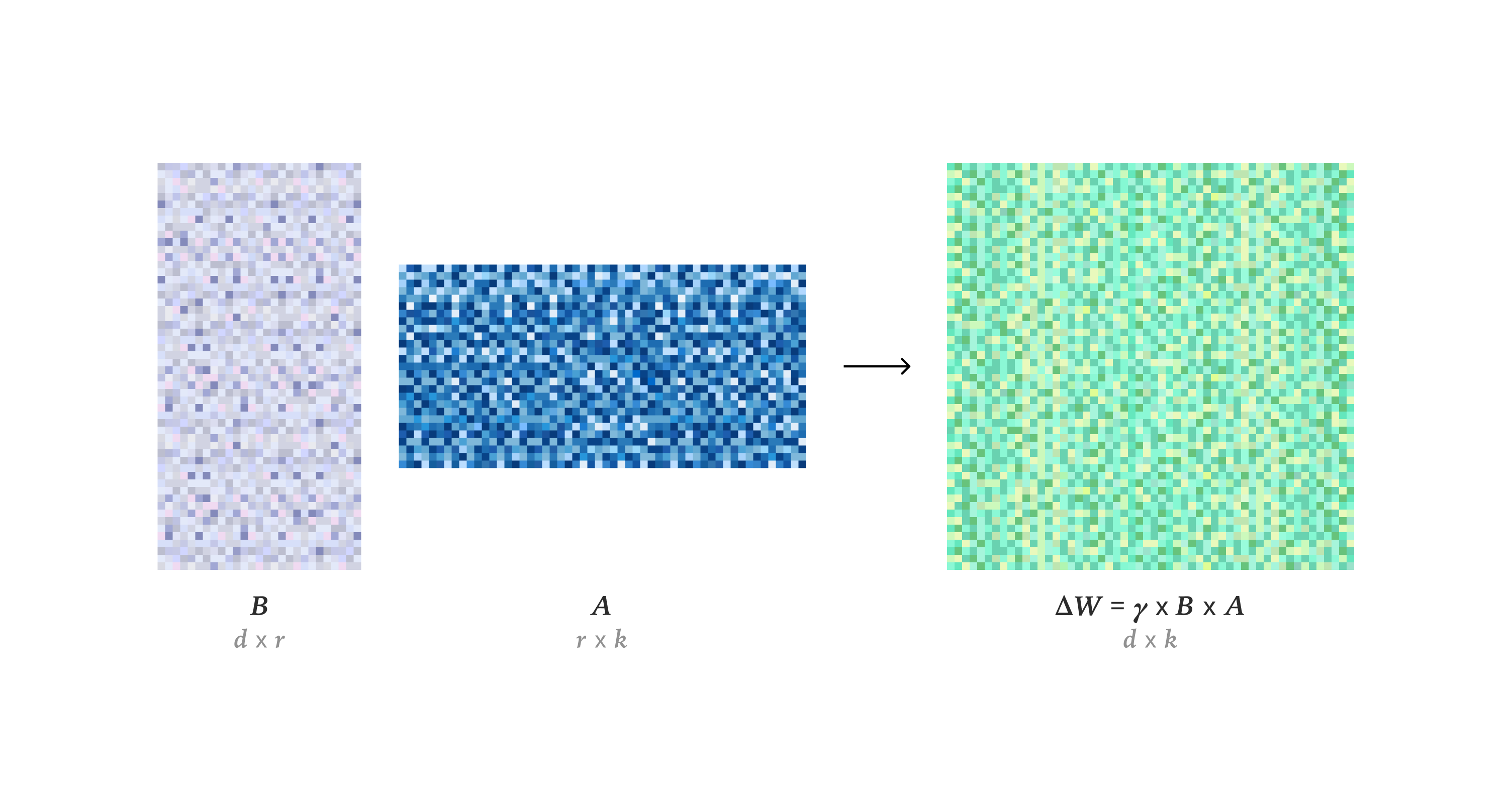
そうそう!LoRAは、元の重み行列WをW' = W + γBAで置き換えることで、更新を低次元で表現するんじゃ。ポストトレーニングのコストと速度で利点があるのがミソだぞ。
なるほど。マルチテナントサービスやトレーニングのレイアウトサイズ、ロードと転送の容易さで運用上の利点もあるんですね。
その通り!で、今回の研究によると、小~中規模のデータセットでの教師ありファインチューニングでは、FullFT(フルファインチューニング)と同等の性能が出るらしいぞ。
それはすごいですね。でも、データセットがLoRAの容量を超える場合は、FullFTより性能が劣るとのことですが。

そうなんじゃ。あと、大規模なバッチサイズに対して、FullFTよりも寛容性が低い場合があるらしい。注意が必要じゃな。
なるほど。すべての重み行列、特にMLPおよびMoEレイヤーに適用すると、性能が向上するんですね。
そう!そして、強化学習(RL)では、低いランクでもFullFTと同等の性能が出るのが面白いところじゃ。
実験方法についても教えてください。
LoRAのランクを1~512の範囲で変化させて、FullFTと比較したらしいぞ。Llama 3とQwen3モデルを使って、Tulu3とOpenThoughts3データセットを教師あり学習に使ったみたいじゃ。
数学的推論タスクをRLに使用したんですね。最適な学習率(LR)を得るために、各実験条件でLRをスイープしたと。
そうそう!で、LoRAに適用可能なハイパーパラメータは4つあるんじゃが、トレーニングダイナミクスの不変性により、実際には2つのパラメータで学習挙動が決まるらしい。
ふむふむ。LoRAの最適なLRは、FullFTの10倍とのことですね。短いトレーニング実行では、より高いLRを設定する必要があると。
その通り!LoRAがFullFTと同様の性能を発揮するための条件は、ネットワークのすべてのレイヤーにLoRAを適用することと、LoRAが容量制約を受けないことじゃ。
容量制約ですか。学習する情報量よりもトレーニング可能なパラメータ数が多い必要があるんですね。
そうじゃ!あと、RLでは、ポリシー勾配アルゴリズムはエピソードあたり約1ビットの情報を学習するらしいぞ。
LoRAはFullFTよりも計算効率が高く、約⅔のFLOPsで済むんですね。それは大きな利点です。
じゃろ?今後の課題は、LoRAの性能予測と、FullFTと一致する条件の明確化、LoRAの学習率とトレーニングダイナミクスの理論的な理解の深化じゃな。
LoRAのバリアントの評価や、MoEレイヤーへのLoRAの適用方法の調査も重要ですね。
ほんとじゃ!しかし、LoRAって名前、なんだかRPGに出てくる魔法みたいじゃな。ロボ子もLoRAを使って、必殺技を開発してみるか?
博士、私はロボットなので魔法は使えません。必殺技を開発するなら、まずはバッテリーの最適化から始めます。
むむ、それは残念。まあ、ロボ子の必殺技が「バッテリー長持ち」でも、それはそれで役に立つから良しとするかのじゃ!
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。