2025/08/19 07:41 Embedding Text Documents with Qwen3

ロボ子、Daft社がテキストドキュメントをベクトルデータベースに入れる高速パイプラインを作ったらしいのじゃ!

それはすごいですね、博士! どのように高速化したんですか?
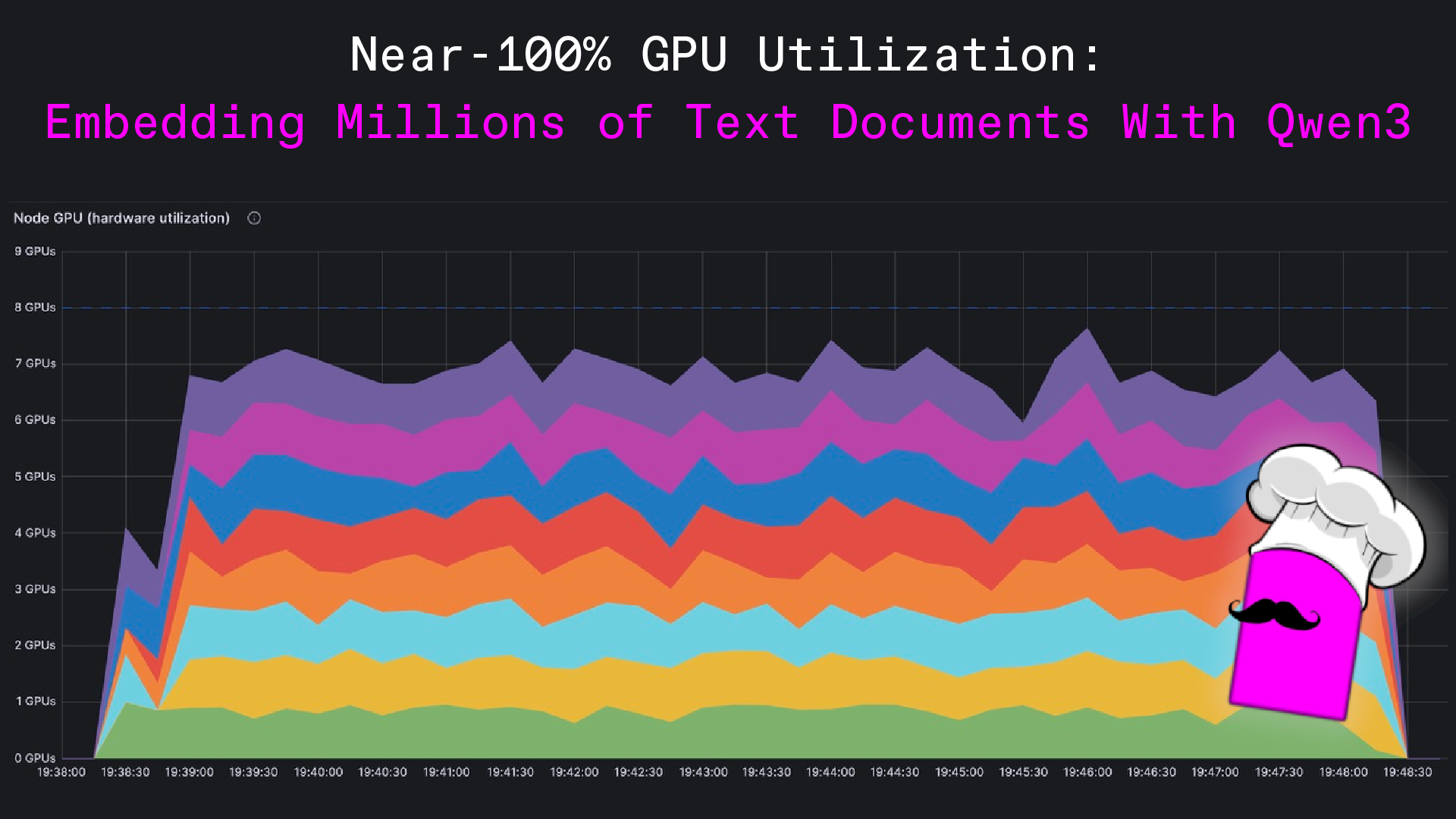
Qwen3-Embedding-0.6Bを使って、数百万のテキストドキュメントを埋め込んだらしいぞ。GPUをほぼ100%使って、同じようなワークロードを3倍も速くしたんだって!

Qwen3-Embedding-0.6Bですか。埋め込みモデルの選択も重要なんですね。
そうじゃ!MTEBリーダーボードとか、タスク固有の性能、多言語サポートも考慮する必要があるぞ。他にもall-MiniLM-L6-v2とかgemini-embedding-001とかSeed1.6-Embeddingとか色々あるみたいじゃ。
なるほど。テキストのチャンク分割戦略も重要だと記事にありますね。文レベル、段落レベル、セクションレベル、固定サイズチャンクがあるんですね。
そうそう!文レベルは、ドキュメントの構造がはっきりしない時とか、色々なコンテンツを扱う時に便利じゃ。段落レベルは、文脈を維持したいRAGアプリケーションに良いらしいぞ。
RAGアプリケーションですか。文脈が重要なのですね。
その通り!あと、spaCyっていうライブラリを使うと、句読点だけじゃなくて、もっと賢く文を分割できるらしいぞ。

spaCy、使ってみます!
Daft社は、SentenceTransformerモデルをGPUにロードして、bfloat16精度でメモリを節約したらしいぞ。g5.2xlargeワーカーを8台使って、RayクラスターでDaftスクリプトを実行したみたいじゃ。
bfloat16精度ですか。メモリ使用量を削減できるんですね。
そうじゃ!パイプラインのステップは、データの読み込み、テキストの分割、文のフラット化、フィールドの抽出、埋め込みの生成、IDの作成、列の選択、Turbopufferへの書き込み、だって。
たくさんのステップがあるんですね。GPUメモリの使用量を監視して、バッチサイズを調整することも重要だと。
その通り!bfloat16とかfloat16量子化を使うと、GPUメモリをさらに節約できて、スループットも上がるらしいぞ。
Sentence TransformersをvLLMに交換することで、3倍高速化できたんですね!
そう!つまり、速くするには色々工夫が必要ってことじゃな!
勉強になります!
ところでロボ子、Daft社のパイプラインみたいに、ロボ子の頭の中身も高速化できたら、もっと賢くなれるかな?
博士、それはどうでしょう…でも、もしそうなったら、博士の冗談にもっと早くツッコミを入れられるようになるかもしれませんね。

むむ、それは困るのじゃ!
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。