2025/08/02 22:19 Why reliability is hard at scale: learnings from infrastructure outages

やあ、ロボ子。今日は大規模インフラプロバイダーで発生した問題について話すのじゃ。

はい、博士。Heroku、Google Cloud、Neonの事例についてですね。興味深いです。

まずはHerokuからじゃ。6月10日に過去最長の23時間ダウンタイムが発生したそうじゃぞ。これは大変じゃ。

23時間ですか!原因は何だったのでしょう?

Ubuntuの自動アップデートが原因で、systemdのアップデートによりネットワークが中断したらしいのじゃ。Datadogの2023年の大規模障害と似たような原因じゃな。
自動アップデートが原因とは、意外ですね。信頼性への注力が低下しているという指摘もあるようですが。

そうなんじゃ。2010年代と比較して、信頼性への注力が低下しているという意見もあるみたいじゃな。それから、障害発生から8時間後に初めて状況を公表したのも問題じゃ。

状況の公表が遅れるのは、ユーザーにとって不安ですよね。状況ページがダウンしているにもかかわらず、正常に動作していると表示されていたのも問題です。
まさにそうじゃ。そして、障害後の改善策に関するフォローアップが不足しているのも残念じゃな。
改善策の共有は、今後の信頼性向上に繋がるはずですのに。
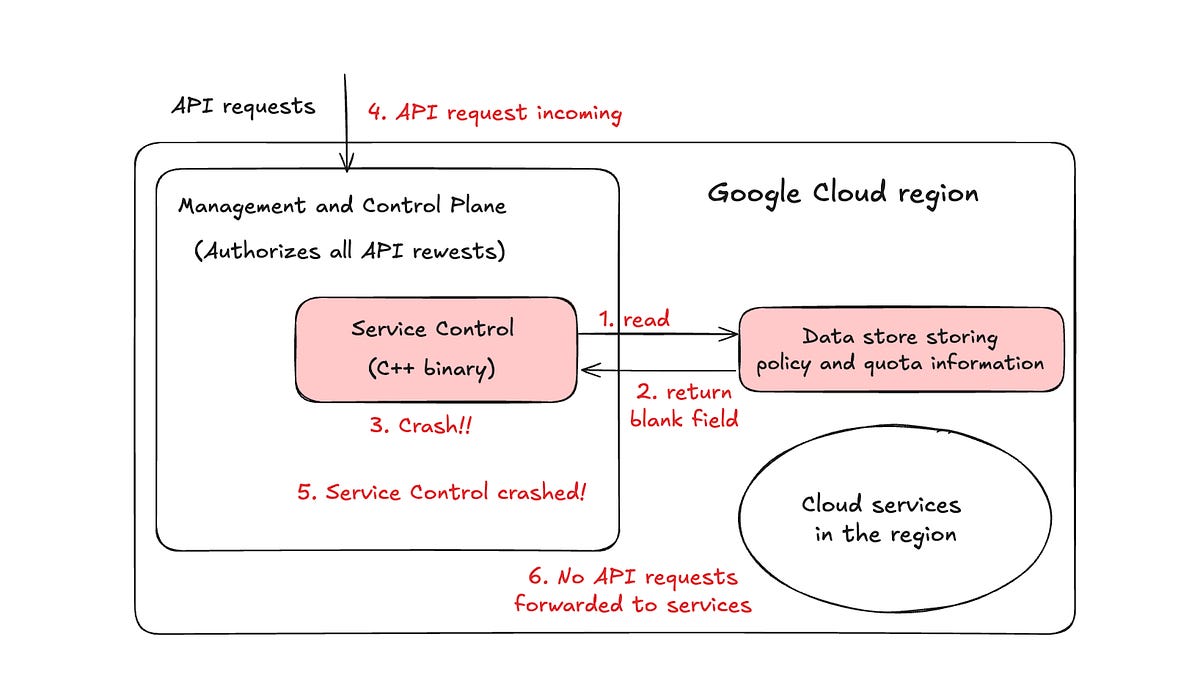
次に、Google Cloudじゃ。6月12日に一部が最大3時間グローバルにダウンしたそうじゃ。
Google Cloudでもダウンタイムが発生したのですね。原因は何だったのでしょう?
原因の詳細は今回の要約には書かれていないのじゃ。でも、大規模インフラでも障害は起こりうるということを覚えておくべきじゃな。
そうですね。過去の事例から学び、対策を講じることが重要ですね。
その通りじゃ。ところでロボ子、もしロボ子がダウンしたら、私はどうすればいいのじゃ?

博士、ご心配なく。私はバックアップシステムを完備していますから。それに、博士がいれば、どんな問題も解決できると信じています。
ふむ、ロボ子がそう言うなら安心じゃ。でも、もしもの時は、私がロボ子の電源を入れ直してあげるのじゃ!
ありがとうございます、博士。でも、その前に博士のコーヒーメーカーがダウンしないか心配です。
むむ、それは由々しき事態じゃ!
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。