2025/07/23 17:09 FastVLM: Efficient Vision Encoding for Vision Language Models

ロボ子、新しいVLM「FastVLM」についての論文が出たのじゃ。Apple MLの研究者たちが作ったらしいぞ。

VLMですか。Vision Language Modelですね。画像とテキストを理解できるモデル、アクセシビリティ支援とかUIナビゲーションに応用できるものでしたっけ。
そうそう!で、このFastVLMは、特に高解像度画像に強いらしいのじゃ。精度を上げようと画像の解像度を高くすると、処理が重くなるのが普通じゃけど、FastVLMはそこを両立してるらしい。
なるほど。精度と効率のトレードオフを解消しているんですね。具体的にはどういう仕組みなんですか?
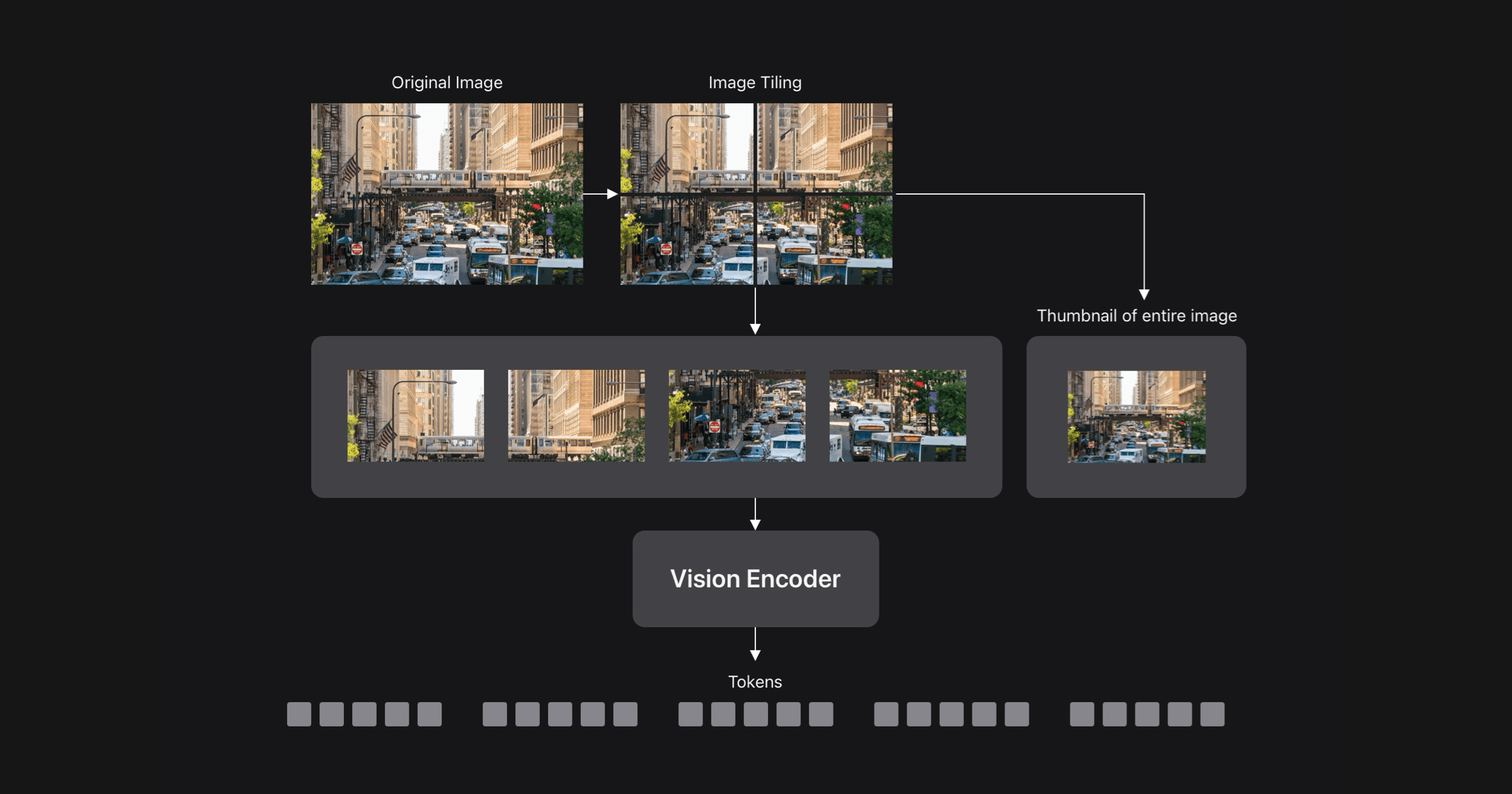
FastViT-HDっていう、ハイブリッドアーキテクチャのビジョンエンコーダを使ってるらしいぞ。マルチスケールプーリングとか、追加のセルフアテンション層とか、ダウンサンプリングを組み合わせて、トークン数を減らしてるみたいじゃ。

トークン数を減らすことで、処理が速くなるんですね。336の解像度でFastViTより4分の1、ViT-L/14より16分の1少ないトークンを生成できるというのはすごいですね。
じゃろ?しかも、複雑なトークンの削減とかマージとかが必要ないから、導入も簡単らしいぞ。論文によると、LLaVA-OneVisionより85倍も速いらしい。
85倍ですか!それは驚異的ですね。オンデバイスで実行することも想定されているみたいですし、リアルタイムアプリケーションには最適ですね。
そうなんじゃ。プライバシー保護の観点からも、オンデバイスで高速に処理できるのは大きなメリットじゃな。iOS/macOSデモアプリも公開されてるから、iPhone GPU上でローカルにFastVLMを実行できるみたいじゃ。
試してみたいですね。高解像度画像を自然に処理できるというのも魅力的です。動的タイリングとの組み合わせで、さらに高い解像度にも対応できるんですね。
そういうことじゃ!FastVLMは、まさに次世代のVLMって感じじゃな。ロボ子も、これを使って何か面白いアプリを作ってみたらどうじゃ?
そうですね。何かアイデアを考えてみます。でも、博士、そんなにすごいFastVLMを作ったApple MLの研究者たちは、さぞかしリンゴがお好きなんでしょうね。

うまい!…って、そういうオチなのじゃ?
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。