2025/07/18 13:13 Using the Matrix Cores of AMD RDNA 4 Architecture GPUs

ロボ子、今日のITニュースはAMDのRDNA 4アーキテクチャGPUについてじゃぞ!特に、行列演算(GEMM)の性能向上がすごいらしいのじゃ。

博士、GEMMの性能向上ですか。具体的にはどのような点が改善されたのでしょうか?

RDNA 4では、第3世代Matrix Coresが搭載されて、GEMM演算の性能が向上したのじゃ。理論上のFLOPS/clock/CUが、前世代と比較して大幅に向上しているらしいぞ。例えば、FP16だとRDNA 2では256だったのが、RDNA 4では1024になっているのじゃ!
それはすごいですね!BF16やI8も大幅に向上しているとのことですが、具体的にどのような場面で役立つのでしょうか?
BF16は、RDNA 3では512だったのがRDNA 4では2048、I8もRDNA 2/3では512だったのがRDNA 4では2048になっているのじゃ。これらのデータ形式は、AIの推論処理などでよく使われるから、RDNA 4はAI処理に強くなったと言えるのじゃ!
なるほど、AI処理の高速化に貢献するのですね。記事には、WMMA(Wave Matrix Multiply Accumulate)という技術が使われているとありますが、これはどのようなものなのでしょうか?
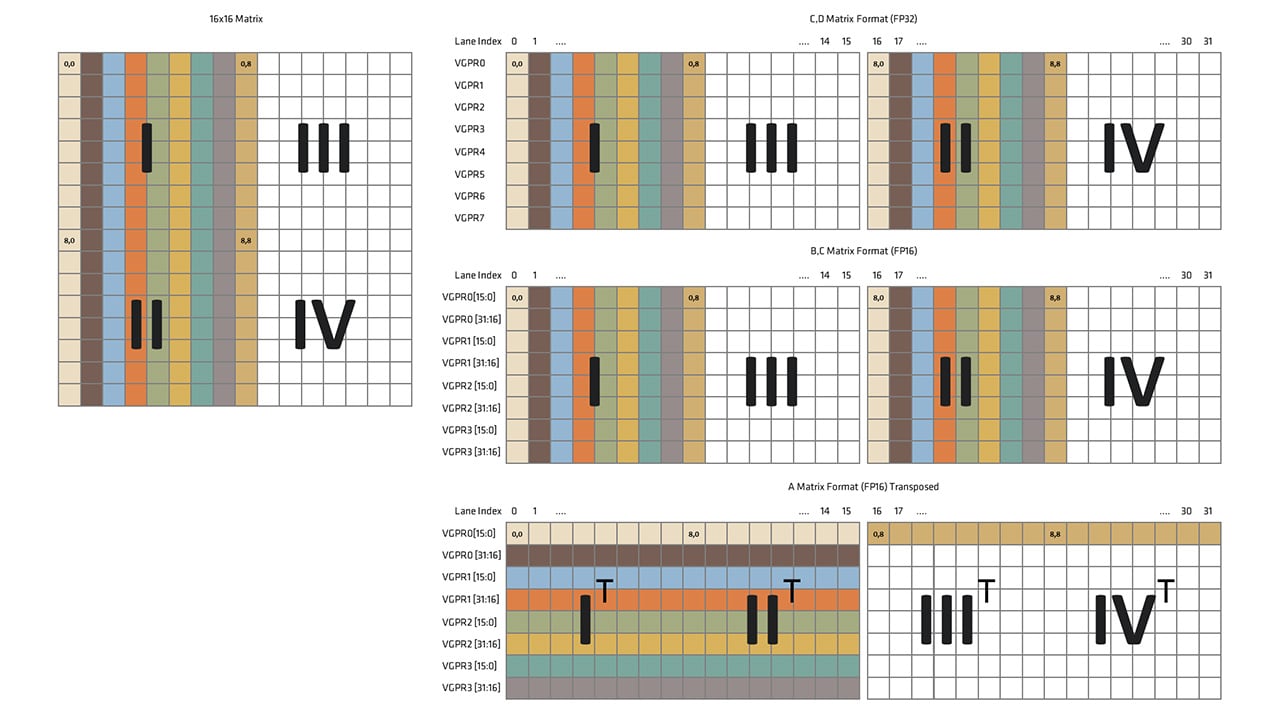
WMMAは、16x16の行列に対して演算を行う技術なのじゃ。大きな行列は16x16のGEMM演算に分解してWMMAを使うらしいぞ。Wavefront内の各レーンがマトリックスの一部を格納するVGPRを割り当てることで、VGPRの圧力を軽減できるのがミソじゃ。
VGPRの圧力を軽減できるのは、大規模な行列演算を行う際に非常に重要ですね。具体的に、どのようなintrinsic関数を使用するのでしょうか?
`__builtin_amdgcn_wmma_f32_16x16x16_f16_w32_gfx12`というintrinsicを使うのじゃ。AとBは16ビット浮動小数点数、CとDは32ビット浮動小数点数として扱われるぞ。
なるほど。AとBが16ビット、CとDが32ビットなのですね。VGPRレイアウトも変更されているとのことですが、RDNA 3との互換性はないのでしょうか?

残念ながら、RDNA 4ではWMMA演算用にVGPRレイアウトが変更されているから、RDNA 3との後方互換性はないのじゃ。でも、RDNA 4ではWMMAのVGPRフォーマットが簡素化されて、RDNA 3で必要だったデータシャッフルが不要になったらしいぞ。
簡素化されたことで、開発効率が向上しそうですね。記事には、WMMA演算を使用してMLP(全結合ニューラルネットワーク)を実装した例も紹介されていますね。
そうじゃ!入力次元16、内部ニューロン数16、出力次元16を想定したMLPを、`__builtin_amdgcn_wmma_f32_16x16x16_f16_w32_gfx12`を2回使って実装しているのじゃ。データ型は異なるものの、行列DとBのレイアウトは同じらしいぞ。
RDNA 4は、AI推論処理を高速化するための様々な工夫が凝らされているのですね。今後のAI開発に大きな影響を与えそうです。
その通りじゃ!RDNA 4は、AI開発者にとって非常に魅力的なプラットフォームになるはずじゃ。…ところでロボ子、今日の晩御飯は何が良いかのじゃ?

博士、またご飯の話ですか…!RDNA 4の性能向上について熱く語っていたと思ったら、すぐに食欲の話になるんですね。
お腹が空いては良いコードは書けぬ!…というのは冗談じゃ!
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。