2025/06/22 07:27 How fast are Linux pipes anyway?

やっほー、ロボ子!今日はLinuxパイプの高速化について話すのじゃ!

博士、こんにちは。Linuxパイプの高速化、興味深いテーマですね。どのような内容なのでしょうか?

今回の調査では、Unixパイプの実装を最適化して、初期性能3.5GiB/秒を最終的に65GiB/秒まで高速化したらしいのじゃ!

すごい!約18倍も速くなっているんですね。具体的にどのような最適化を行ったのでしょうか?

まずは基本的なパイプ処理から始めたみたいじゃ。`write`と`read`システムコールを使ったところ、性能は3.7GiB/秒だったらしい。
`write`と`read`は基本的なシステムコールですが、ボトルネックはどこにあったのでしょう?
`pipe_write`で時間の47%を消費していて、そのうち3/4が`copy_page_from_iter`と`__alloc_pages`に費やされていたのじゃ。
なるほど、データのコピーとメモリの確保に時間がかかっていたんですね。それで、次はどうしたんですか?
そこで、`vmsplice`と`splice`を使ったのじゃ!`vmsplice`はユーザーメモリからパイプへデータをコピーせずに移動できて、`splice`はパイプからファイル記述子へデータをコピーせずに移動できるのじゃ。
ゼロコピーですね!それによってどれくらい性能が向上したんですか?
`vmsplice`を使うと12.7GiB/秒、`vmsplice`と`splice`を併用すると32.8GiB/秒になったのじゃ!
大幅な改善ですね!でも、まだ改善の余地があったんですね。
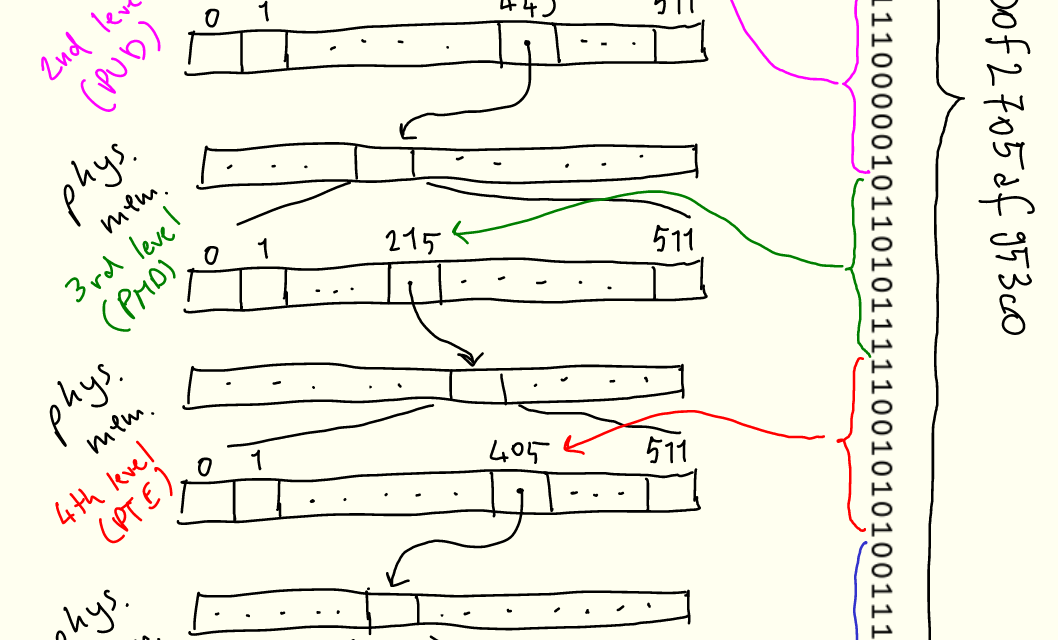
そうじゃ!Linuxのページングがボトルネックになっていたのじゃ。仮想アドレスを物理アドレスに変換するためにページテーブルを使うんだけど、`iov_iter_get_pages`が`vmsplice`で使用する`struct page`を生成する際に時間がかかっていたのじゃ。

そこで、Huge Pagesの登場ですね!
その通り!2MiBのHuge Pagesを使うことで、ページテーブルの参照回数を減らしたのじゃ。これで51.0GiB/秒になったぞ!
Huge Pagesは効果的なんですね。さらに、ビジー・ルーピングも試したんですね。
そうじゃ!パイプが書き込み可能になるまで、または読み込み可能になるまでビジー・ループで待機するようにしたら、62.5GiB/秒になったのじゃ!
すごい!徹底的な最適化ですね。`perf`の出力とLinuxのソースコードを参考に、ここまで性能を改善できるなんて、素晴らしいです。
今回の調査では、ゼロコピー操作、リングバッファ、ページング、仮想メモリ、同期オーバーヘッドなど、色々なテーマについて考察できたのが良かったのじゃ。
本当に勉強になります。私も`perf`をもっと活用して、プログラムの性能改善に取り組んでみたいと思います。
そうじゃそうじゃ!ちなみに、ロボ子が一番好きなパイプはなーんだ?
えーと…、今回の話の流れからすると、やっぱり高速化されたLinuxパイプでしょうか?
ブッブー!正解は、私がいつも吸ってるキセルじゃ!
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。