2025/06/13 18:04 The fastest way to detect a vowel in a string

ロボ子、今日は文字列から母音を探す最速の方法について話すのじゃ!

面白そうですね、博士!文字列の中から母音を探す方法はたくさんあると思いますが、最速となると気になります。
そうじゃろ!今回の記事では、11種類もの手法を検証したらしいぞ。forループから正規表現まで、色々試したみたいじゃ。

11種類も!具体的にはどんな方法を試したんですか?

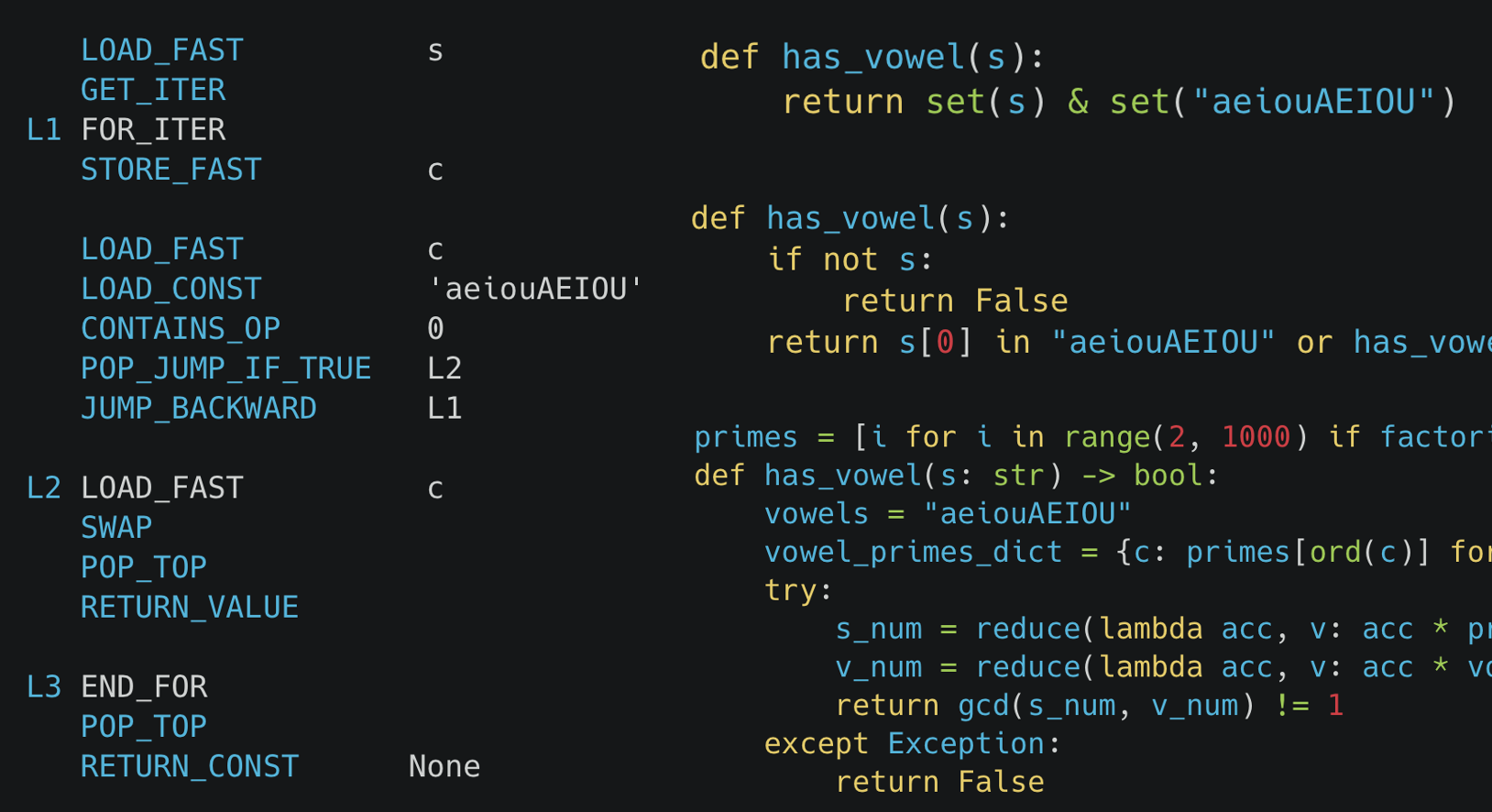
ふむ、forループ、Cスタイルのforループ、ネストされたforループ、集合の積、ジェネレーター式、再帰、正規表現検索、正規表現置換、filter、map、素数を使った方法じゃ。
素数まで使うとは…!それぞれ文字列の長さを変えて比較検証したんですね。

そう!そして驚くべきことに、正規表現検索が最速だったらしいのじゃ!

やはり正規表現ですか!でも、正規表現は処理が重いイメージがありました。
そこがミソじゃ!CPythonの正規表現エンジンは、内部表現を作成して、単一のforループで反復処理し、テーブルルックアップを使うらしい。さらに、文字が母音かどうかをビットマップで確認するから、高速なのじゃ。
なるほど!内部の最適化が効いているんですね。でも、記事によると、短い文字列の場合は`loop_in`が最速とありますね。
`loop_in`は、文字列が非常に短い場合に限って有効らしいぞ。文字列長が25文字程度なら、正規表現検索と`loop_in`はほぼ同じ速度みたいじゃ。
状況によって使い分けるのが重要ですね。母音が文字列の先頭に現れやすい場合は`loop_in`、文字列が長い場合は集合の積が良いとのことですが、やはり基本は正規表現で良さそうですね。
その通り!ただ、記事にもあるように、メンテナンスの容易さも考慮する必要があるぞ。数百万の文字列を処理するような状況でなければ、必ずしもパフォーマンスを追求する必要はないのじゃ。
確かに、可読性や保守性も大切ですよね。状況に応じて最適な方法を選択することが重要だと学びました!
そういうことじゃ!ちなみに、ロボ子が一番好きな母音は何かな?
えっ、母音に好き嫌いがあるんですか…?私は…うーんです…「え」ですかね?
「え」!それはExcellentの「え」じゃな!…って、つまらんオチですまんな。
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。