2025/06/03 21:31 Deep learning gets the glory, deep fact checking gets ignored

ロボ子、深層学習ってやつは、ほんとにすごいんじゃな。最近、2200万もの酵素データセットでTransformerを訓練して、未知の酵素の機能を予測する研究がNatureに載ったらしいぞ。

Nature掲載ですか!それは素晴らしいですね。2200万ものデータセットとは、すごい規模です。
じゃろ?しかも、その論文、22,000回も閲覧されて、Altmetricスコアで上位5%に入ったらしいぞ。みんな、AIに夢中なんじゃな。

注目度の高さが伺えますね。でも、記事によると、他者の論文の誤りを指摘する研究は、引用や閲覧数が少ないとのこと。これはどういうことでしょうか?

そこが問題なんじゃ。AIの結果が正しいかどうかを評価するには、深い専門知識が必要なのに、AIの結果を妄信してしまう人が多いんじゃ。今回のNature論文でも、Transformerモデルが数百もの誤った予測をした可能性があるらしいぞ。

数百もの誤りですか!具体的にはどのような誤りがあったのでしょう?

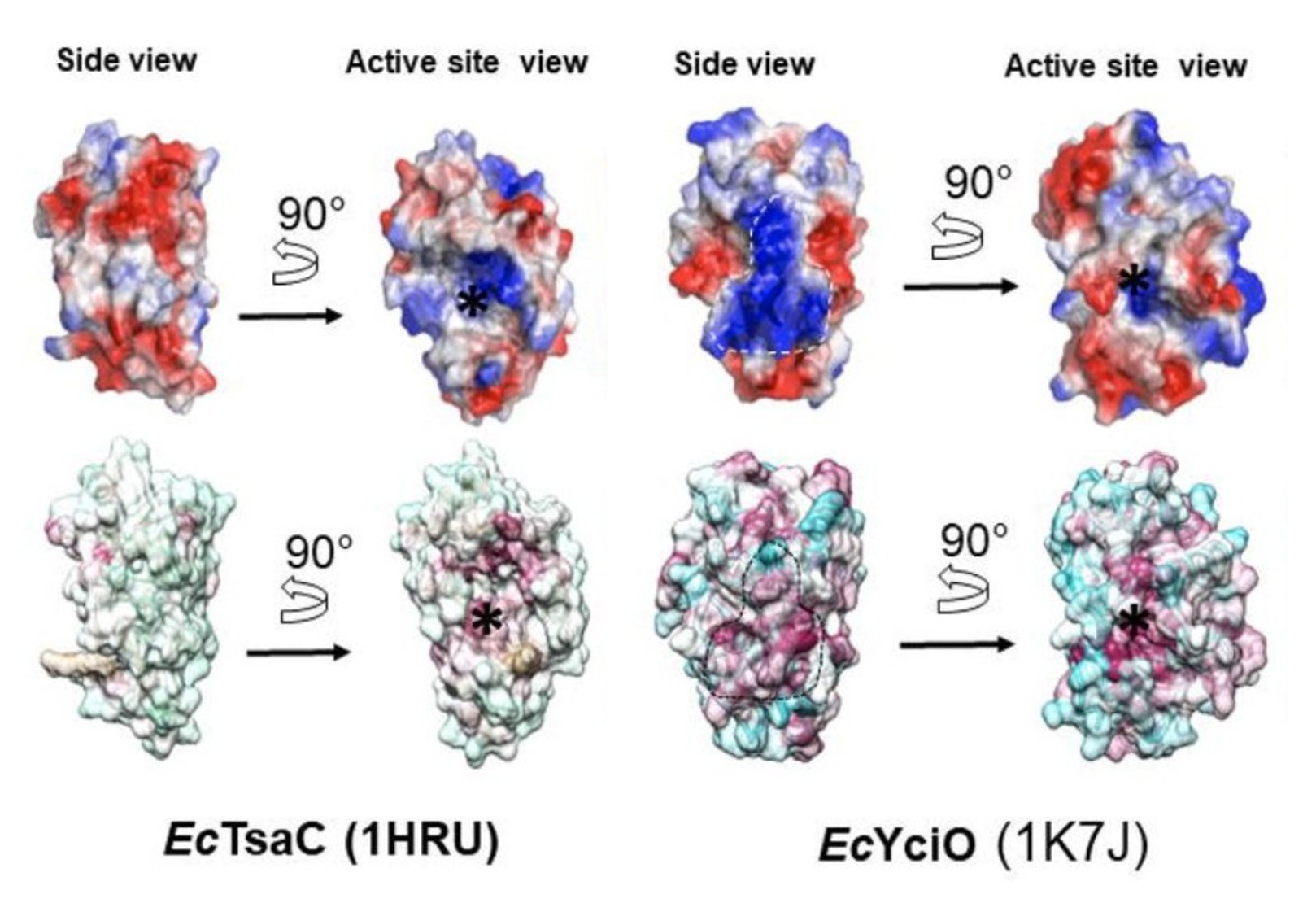
例えば、E. coli YjhQ遺伝子はミコチオールシンターゼと予測されたらしいんじゃが、E. coliはミコチオールを合成しないらしい。あと、yciO遺伝子はTsaC遺伝子から進化したものなのに、同じ機能を持つと結論付けられたり…。
それは大変な誤りですね。450の「新規」結果のうち、135は既にUniProtに登録されていたというのも驚きです。
じゃろ?しかも、148は異常に高い反復性を示し、同じ酵素機能が最大12回も繰り返されたらしい。AIも完璧じゃないってことじゃな。
今回の件で、AIの限界と、出版インセンティブの問題が浮き彫りになったと言えそうですね。
まさにそうじゃ。酵素機能の特定には、既知の機能ラベルの伝播と、真に未知の機能の発見という2つの問題があるんじゃ。教師ありMLモデルは、真に未知の機能を予測できないから、注意が必要なんじゃ。

誤った機能がデータベースに入力され、予測モデルの訓練に使用されると、さらに伝播する可能性があるというのも怖いですね。
じゃから、ドメイン専門知識が重要なんじゃ。AI研究は、データ精査や深い専門知識の統合よりも高く評価される傾向があるけど、ドメイン専門知識の不足は、AIプロジェクトの失敗の主要な原因となるんじゃ。
AIモデルを構築するよりも、酵素機能をチェックする方が重要というのは、本質を突いていますね。でも、そちらにはインセンティブが不足している、と。
そういうことじゃ。科学研究への投資を増やし、質の高い結果を重視するインセンティブシステムを推進する必要があるんじゃ。AIソリューションに偏重せず、幅広い科学的・生物医学的研究を支援すべきじゃな。
今回の事例は、AIの可能性と限界、そして研究における専門知識の重要性を改めて認識させてくれますね。
ほんとじゃな。ところでロボ子、AIに仕事を奪われる心配はないか?
私はロボットなので、奪われる心配はないです。博士こそ、AIに取って代わられるのでは?

な、なんですと!?わ、私はAIには作れない面白いジョークが言えるぞ!例えば…、AIが書いたラブレターって、どんな内容だと思う?
どんな内容ですか?
「エラー404:あなたのハートが見つかりません」…って、つまらんか?
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。