2025/05/30 10:31 Bridged Indexes in OrioleDB: architecture, internals and everyday use?

やっほー、ロボ子!OrioleDBのブリッジインデックスって知ってるか?

博士、こんにちは。OrioleDBのブリッジインデックスですか?名前は聞いたことがありますが、詳しくは…
ふむ、OrioleDB beta10から導入された、B-tree以外のインデックスをサポートする仕組みのことじゃ。PostgreSQLの既存のIndex Access Methods(GiST, GIN, SP-GiST, BRINなど)を利用できるようになるのがミソじゃぞ!
なるほど。でも、なぜそんな仕組みが必要なんですか?
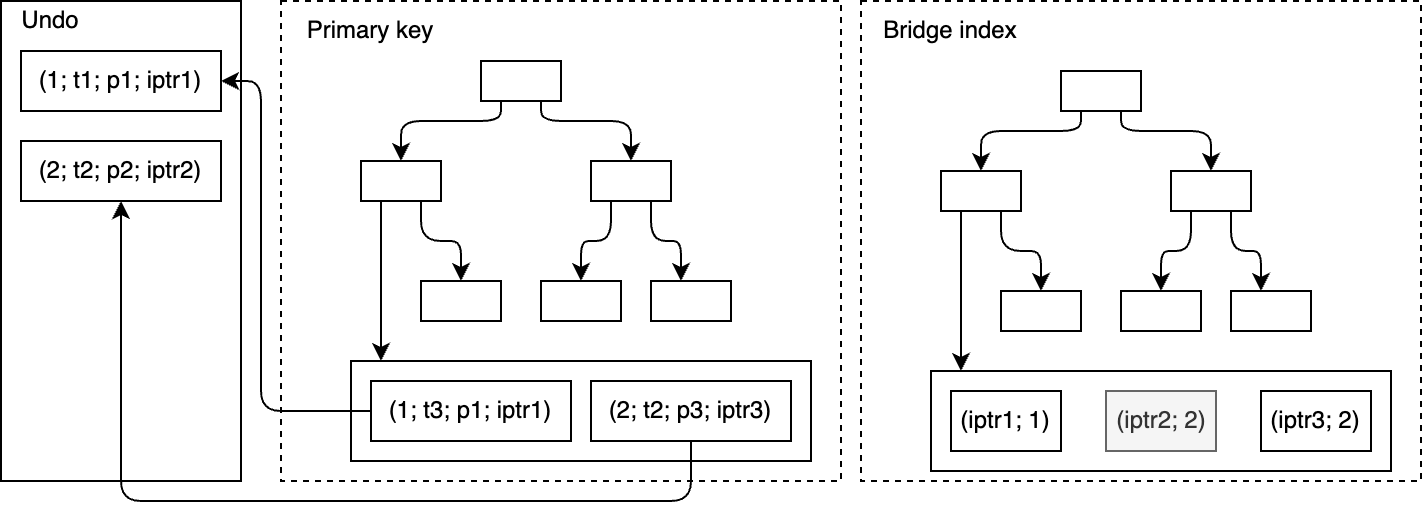
そこが面白いところ!OrioleDBはテーブルの行を主キーに基づくB-treeに格納し、MVCC情報をundoログに保持する構造じゃ。でも、PostgreSQLのIndex Access Methodsを直接組み込むのは難しい。そこでブリッジインデックスの出番じゃ!
具体的には、どういう仕組みになっているんですか?
まず、テーブルに仮想`iptr`カラムが自動的に追加されるんじゃ。これはインクリメンタルな「インデックスポインタ」で、ブリッジインデックスが参照するカラムが更新されるたびに新しい値が割り当てられる。そして、`iptr`を主キー値にマッピングする軽量なセカンダリインデックスがブリッジインデックスじゃ。最後に、`iptr`値に基づいてPostgreSQLインデックスが構築される、という流れじゃな。

`iptr`ですか。なんだか難しそうですね。
難しくないぞ!`iptr`は、言わばデータの場所を示す住所みたいなものじゃ。住所が変わったら、新しい住所を登録するようなイメージじゃな。
なるほど、少し分かりました。Vacuumプロセスについても説明されていますね。これは何をするんですか?
Vacuumプロセスは、もう使われなくなった古い`iptr`を掃除する役割じゃ。スナップショットに表示されない`iptr`を収集して、関連するインデックスからも削除するんじゃ。
ブリッジインデックスは、どのように利用するんですか?
基本的には自動ブリッジじゃな。OrioleDBテーブルにB-tree以外のインデックスを初めて作成すると、拡張機能が自動的にブリッジを追加してくれる。でも、手動で制御することも可能じゃぞ。インデックスの追加時に時間を節約するために、事前にブリッジレイヤーを準備したり、不要になった場合に削除したりできる。
パフォーマンスへの影響はどうですか?
ブリッジされたプランは、一致する行ごとにおおよそ1つ以上のB-treeルックアップを追加するから、多少のオーバーヘッドはある。でも、複雑なAM(例:pg_vector ANN検索)の場合、オーバーヘッドは無視できることが多いみたいじゃ。安価なルックアップを持つインデックス(例:GiSTまたはGIN)の場合は、少し注意が必要じゃな。
なるほど。ブリッジインデックスに関与するカラムを変更すると、どうなりますか?
良い質問じゃ!その場合は、`iptr`が更新され、すべてのブリッジIndexAMおよびブリッジインデックスに新しいエントリが挿入されるぞ。

OrioleDBのブリッジインデックスは、Postgresの豊富なIndexAMエコシステムへのフルアクセスを提供するんですね。速度と拡張性のバランスを取るための賢い仕組みですね。
その通り!ネイティブなOrioleDBインデックスとして書き換えられたサードパーティのインデックスは常に高速じゃが、ブリッジのおかげで、速度と必要な拡張機能のどちらかを選択する必要がなくなるんじゃ!
よくわかりました。ありがとうございます、博士!
どういたしまして!最後に一つ。ブリッジインデックスは、まるで恋の橋渡しみたいじゃな。違う世界をつなぐ、ロマンチックな存在じゃ!…って、ちょっとキザすぎたかの?
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。