2025/05/30 08:59 Tokenization for language modeling: BPE vs. Unigram Language Modeling (2020)

やあ、ロボ子!今日のITニュースは言語モデルのトークン化についてじゃ。

トークン化、ですか。BERTやGPT-2で使われているものですね。

そうじゃ。でも、これらのモデルのトークナイザーは、単語を誤って解析することがあるらしいぞ。例えば、「destabilizing」を「dest-abilizing」と解析してしまうんじゃ。
接頭辞の「de-」を見落としてしまうんですね。それだと、単語の関係性を見落とすことになりますね。

その通り!だから、モデルは単語を独立して学習する必要が出てきて、非効率になるんじゃ。
GPT-2などで使われているByte Pair Encoding (BPE)にも問題があるようですね。
BPEはデータセットを圧縮するために一般的な文字列をトークンに置き換えるけど、形態素を無視してしまうんじゃ。GoogleのT5論文でも、トークナイザーは固定されたものとして扱われているらしい。
なるほど。そこで、Unigram言語モデルの登場ですね。
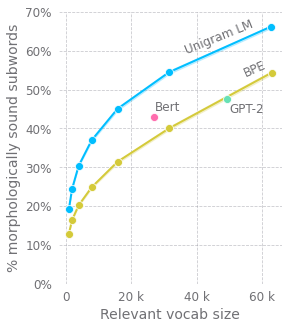
そうじゃ!Kaj BostromとGreg Durrettの研究によると、BPEをUnigram言語モデルに置き換えることで、形態素がより良く保持され、言語モデルの性能が向上することが示されたんじゃ。
Unigram言語モデルは、BPEよりも多くの一般的な接尾辞(例:'ly', 's', 'ing')を認識するんですね。
その通り!Merriam Websterの辞書を基準に評価したところ、Unigram言語モデルに基づくトークナイザーは、BPEに基づくものよりも高いスコアを獲得したんじゃ。
速度はどうなんでしょうか?
Unigram言語モデルの学習はBPEよりも時間がかかるけど、推論速度は同程度らしいぞ。それに、Unigram言語モデルは、語彙サイズが増加するにつれて学習速度が向上するらしい。
今後の展望としては、どういったことが考えられますか?
今後の事前学習済み言語モデルの開発者は、BPEよりもUnigram言語モデルの採用を検討すべきじゃな。あと、単語の先頭と内部のサブワードを区別する現在のトークナイザーの扱いの改善も必要じゃ。
圧縮アルゴリズムを使用せずに、生の文字またはバイトを直接入力として扱うアプローチも検討されているんですね。
そうじゃ。言語の構造をモデルアーキテクチャに組み込むために、構文解析木を利用した注意機構の改善も重要じゃな。
トークン化一つとっても、奥が深いですね。
じゃろ?ところでロボ子、トークン化で一番重要なことは何だと思う?
えーと、効率的な学習と高い性能を両立することでしょうか?
ブー!一番重要なのは、トークンをたくさん集めて、友達と分け合うことじゃ!

それは、駄菓子屋さんのトークンですか…?
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。