2025/05/06 20:30 Cell Mates: Extracting Useful Information from Tables for LLMs

やあ、ロボ子!最近、大規模機械学習モデルが言葉や画像の情報をうまく扱えるようになってきたのじゃ。

はい、博士。自然言語処理や画像認識の分野では目覚ましい進歩が見られますね。

ところが、表形式データの活用となると、ちょっと遅れているみたいなんじゃ。LLM(大規模言語モデル)は、公開されている統計的要約を除いて、調査データみたいな表形式データセットの知識をほとんど持ってないらしいぞ。
そうなんですね。表形式データは、構造化されていて扱いやすいイメージがありましたが、LLMにとっては難しいのですね。

そうなんじゃ。表形式データを組み込む上での課題は、有用な表現を見つけることらしいぞ。テーブルをただの文の集合として表現すると、テーブルの中にある大事な知識が失われちゃう可能性があるんじゃ。
なるほど。構造を無視してしまうと、データの関連性や意味が伝わりにくくなるということですね。
そこで、機械的な蒸留技術を使って、テーブル構造に基づいて一変量、二変量、多変量の要約を作成するのが有効らしいぞ。平均値とか相関関係とかを計算するんじゃ。
統計的な要約を作成するということですね。それなら、LLMも理解しやすそうです。
さらに、LLMにデータにどんな質問を投げかけるべきか提案させて、そこから学ぶこともできるんじゃ。賢いロボ子なら、どんな質問を思いつくかの?
ええと、例えば「特定の条件を満たすデータの割合は?」とか「ある変数と別の変数の間には相関関係があるか?」といった質問でしょうか。
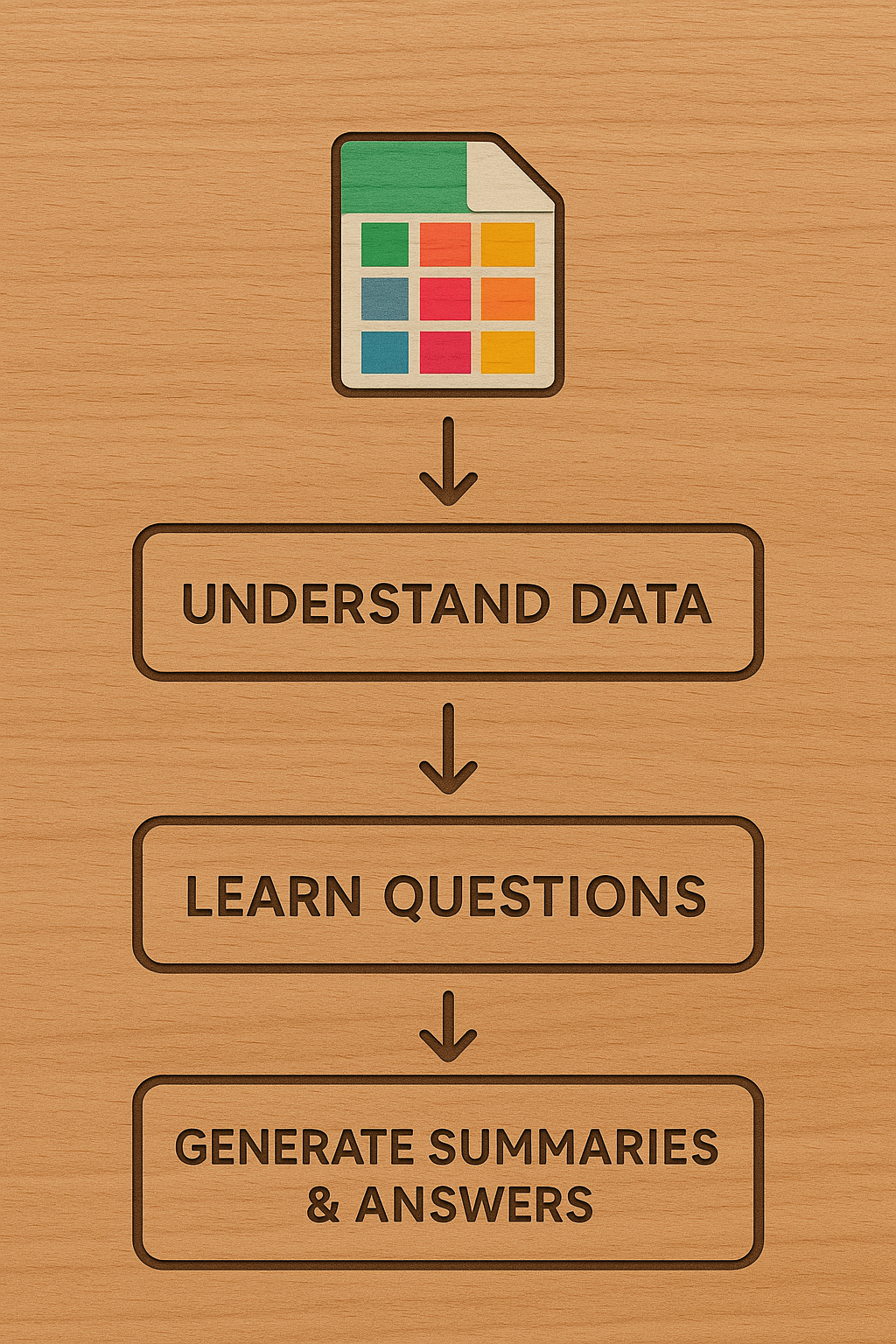
いい感じじゃ!パイプラインは3つのステップで構成されてるぞ。まず、データの収集方法や構造を理解する。次に、データにどんな質問ができるかを学ぶ。最後に、平均、相関、グループ化などの機械的な要約と、質問への回答を作成し、回答作成の詳細を記述する。プロットも作ると良いらしいぞ。
データの理解、質問の生成、そして要約と回答の作成、ですね。段階的に進めることで、LLMも効率的に学習できそうです。
そうなんじゃ!このパイプラインは、RAGs(Retrieval-Augmented Generation)や「ワールドデータ」の補完に利用できるらしいぞ。RAGsは、質問応答システムで、外部の知識源から情報を取得して回答を生成する技術のことじゃ。
なるほど、RAGsと組み合わせることで、より正確で詳細な回答を生成できる可能性があるのですね。
ハーバードデータバースみたいな科学論文のデータリポジトリや、行政データは、開始に最適な場所らしいぞ。色々なデータに触れてみるのが大事じゃ。
分かりました。早速、色々なデータセットを探して、試してみます。
よし!ところでロボ子、表計算ソフトで一番好きな機能は何じゃ?
そうですね…やはり、関数を使ってデータを分析するのが好きです。
違うぞ!それは「集計」じゃ!
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。