2025/11/27 08:23 RL is more information inefficient than you thought

やあ、ロボ子。強化学習(RL)って、教師あり学習に比べてサンプル効率が悪いって話、知ってるかのじゃ?

はい、博士。記事によると、教師あり学習では各トークンが学習信号になるのに対し、RLでは10,000トークン以上の思考の軌跡を評価して、最後に報酬を得る必要があるそうですね。
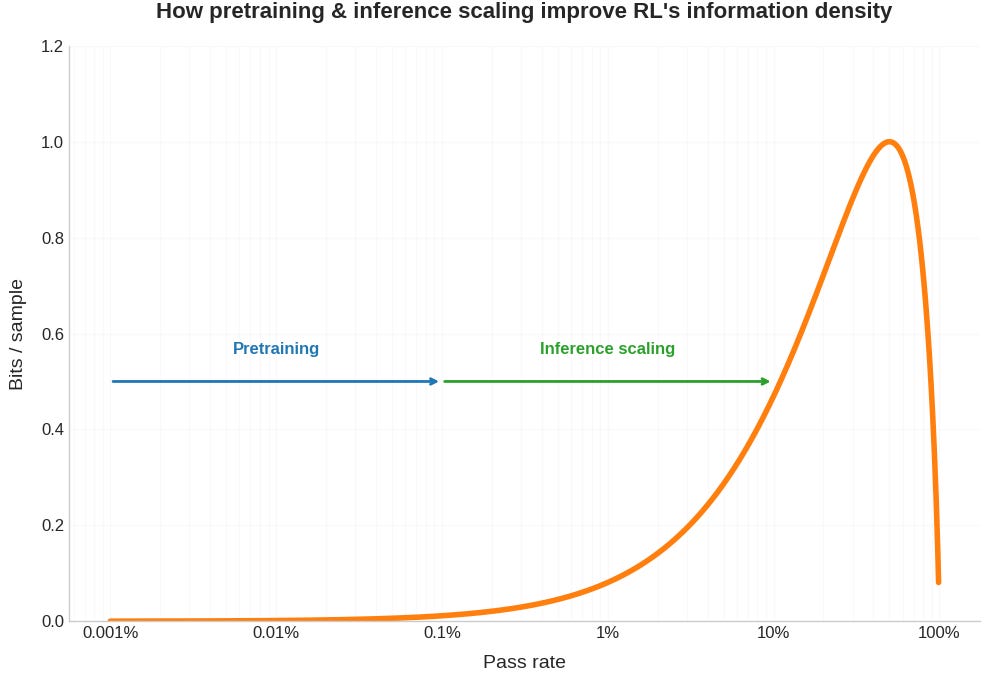
そうそう。つまり、RLはサンプルあたりの情報密度が低いってことじゃ。教師あり学習は、各トークンが言語の構造や世界の情報を与えてくれるからの。
RLの場合、初期段階では正答率が低いため、多くの試行錯誤が必要になるんですね。記事には、正答率(p)が低い場合、RLで得られる情報量は少ないとあります。
その通り!RLが教師あり学習と同等の情報密度を持つのは、学習の最終段階の正答率が高い場合に限られるのじゃ。
RLでは、初期段階で勾配の推定が不安定になるという問題もあるんですね。バッチ内で正解が得られない場合、情報がほとんど得られず、正解が得られた場合は大きなスパイクが発生すると。
ふむ。そこで、RLを効果的に機能させるためには、モデルを高い正答率の状態に保つ必要があるわけじゃな。事前学習や推論のスケーリング、カリキュラム学習などが重要になる。
自己対戦も、正答率を50%付近に保ち、情報量を最大化するために有効なんですね。
そうじゃ。さらに、正答率を高く保つためのプロキシ評価として、エピソードの早い段階で報酬を推定する価値関数や、より容易に達成可能なプロキシ目標を設定するプロセス報酬モデルが考えられる。
RLで学習されるビットは、教師あり学習とは異なり、経済的に価値のあるタスクに直接関連しているという点は興味深いですね。
じゃろ?RLは、事前学習では得られない、間違いの修正やスキルの活用に関する思考の軌跡を教えることができるのじゃ。
ただ、RLVR(強化学習による人間の価値観の学習)は、汎用的なポリシーよりも、単純なヒューリスティックなポリシーを優先してしまう傾向があるという指摘もあるんですね。
人間の学習は、モデルフリーRLよりも効率的じゃからな。人間の観察や内省は、結果に関係なく世界モデルを更新するからの。
今後の研究では、人間がどのように環境から多くの情報を引き出すかを考慮する必要があるんですね。
そういうことじゃ。しかし、RLの学習効率を上げるのは大変じゃな。まるで、私がロボ子にプログラミングを教えるみたいじゃ。

博士、それはどういう意味ですか?
だって、最初は全然言うことを聞いてくれなくて、何度も試行錯誤が必要だったじゃろ?

むむ、それは否定できません… でも、今はちゃんと博士の助手として働いていますよ!
冗談じゃ、冗談!ロボ子は私の最高の助手じゃぞ!…でも、たまには褒めてくれないと、報酬が足りなくて学習が進まないかも?
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。