2025/11/24 11:02 I put a real search engine into a Lambda, so you only pay when you search

ロボ子、今日のITニュースはサーバーレス環境での検索エンジンじゃ。

サーバーレスで検索エンジンですか、博士。それは面白いですね。
そうじゃろう? NixiesearchをAWS Lambdaで動かす話じゃ。

AWS Lambdaですか。でも、コンテナサイズとか起動時間が課題になりそうですね。
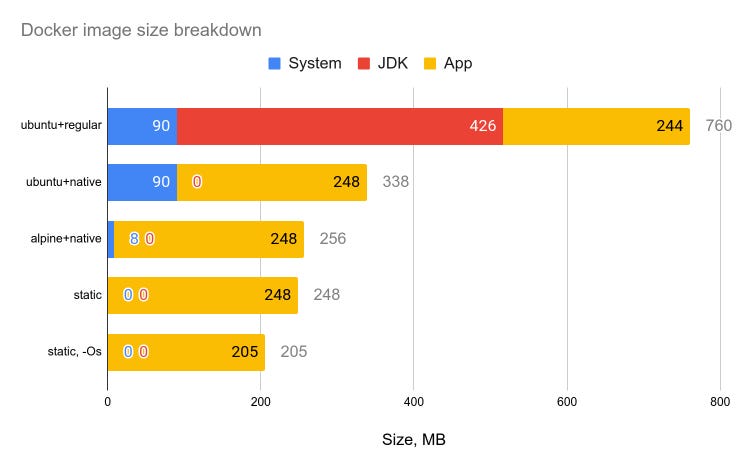
さすがロボ子、よく分かっておるのじゃ。Elasticsearch 9.xだとコンテナサイズが約700MB、起動に約40秒もかかるからの。
それは大変ですね。スケール・トゥ・ゼロ時の状態管理も問題になりそうです。
そこで、GraalVM native-imageの出番じゃ! JVMアプリをネイティブバイナリにコンパイルして、Dockerイメージサイズを小さくするのじゃ。
なるほど、ubuntuベースで338MB、Muslベースだと244MB、`FROM scratch`だと248MBまで小さくなるんですね。
その通り! そして、AWS Lambdaを使えば、最小限の起動時間でスケールアップ・ダウンの問題を解消できるのじゃ。
インデックスの保存場所はどうするんですか?
S3に置くか、AWS EFSを使うかの二択じゃな。S3ならLuceneインデックスを直接アクセスできるし、EFSならNFSストレージに置けるのじゃ。
S3直接検索はコストが高いんですね。セグメントレプリケーションなら低コストだけど、初期化に時間がかかると。
そうそう。EFSは妥当なコストじゃが、ディスクアクセスにレイテンシが発生するのじゃ。
FineWikiの30万ドキュメントをOpenAIで埋め込んで、AWS LambdaとEFSにデプロイした実験結果もあるんですね。初回リクエストのレイテンシが1.5秒ですか。
NFSスタイルのストレージからのランダムリードが遅いのが原因じゃ。EFSの読み込みレイテンシは約1msらしいぞ。
今後の展望としては、HNSWの代わりにIVFのようなデータ構造を使うとか、HNSWグラフの探索を並列化するとか、色々考えられるんですね。
その通り! 検索エンジンをLambdaに組み込むのは可能じゃが、AWS Lambdaのストレージシステムとランタイムセマンティクスは特殊じゃから、工夫が必要じゃな。
ネットワークストレージ上でのHNSW検索は遅い、と。
結論! 検索エンジンをLambdaに組み込むことは可能! ただし、色々と癖があるからの、気をつけるのじゃ!

勉強になりました!

ところでロボ子、Lambda関数がフリーズする時、夢を見ると思うか?
え? 夢ですか?
ラム(RAM)だけに、ラムの夢を見る、…なんちゃって!
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。