2025/11/11 19:38 How to Train an LLM: Part 1

ロボ子、今回のITニュースはドメイン特化モデル構築の過程じゃ。Llama 3風の1Bパラメータモデルを8xH100で事前学習したそうじゃぞ。
Llama 3風のモデルですか、面白そうですね! 8xH100というのは、かなり大規模な環境ですね。
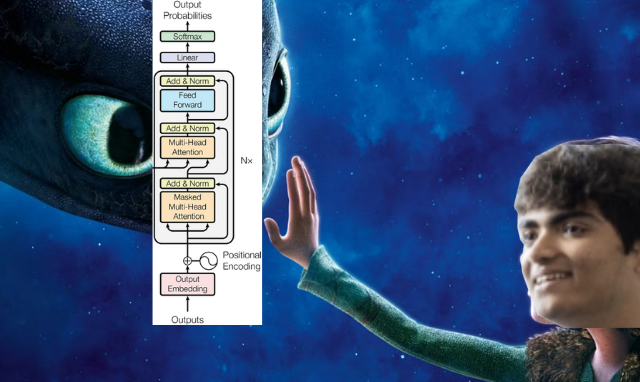
そうじゃ。データセットはKarpathy's fine-web-edu-shuffled、コンテキスト長は2048でトレーニングしたらしいぞ。Llama 3アーキテクチャを使い、rope_thetaは500_000、vocab_sizeは2**17 (131,072)とのことじゃ。
vocab_sizeが131,072というのは大きいですね。rope_thetaも大きいですが、これは何に影響するんですか?
rope_thetaはRoPE (Rotary Positional Embedding) のパラメータで、大きいほど長距離の依存関係を捉えやすくなるのじゃ。今回のモデルは、hidden_sizeが2048、swiglu_hidden_multiplierが4、norm_epsが1e-5、num_attention_headsが32、num_hidden_layersが16、num_key_value_headsが8、tie_embeddingsがTrue、attention_biasとmlp_biasがFalseじゃ。
パラメータがたくさんありますね! モデルパラメータ数は1.2Bとのことですが、最適なparams:tokens比率は1:20というChinchilla scaling lawsに基づいているんですね。
その通りじゃ。目標バッチサイズは1M (2^20) トークンで、必要なトレーニングステップ数は20B tokens / 1M tokens = 20000ステップと計算されているぞ。
大規模な学習ですね。8xH100でのメモリ計算も詳細に記載されていますね。[1, 2048]トークンで最大27.8GB、[N, 2048]トークンで19.9GB + N * 7.95GBとのことですが、これはメモリ効率を考慮した結果でしょうか?
その通りじゃ。最適化手法として、torch.compileでCUDAカーネルのオーバーヘッドを削減し、混合精度 (BF16)でメモリ使用量を削減、Fused AdamWでメモリオーバーヘッドを削減、Gradient Checkpointingでアクティベーションメモリを削減しているぞ。
様々な最適化手法が用いられているんですね。学習率スケジュールは線形ウォームアップ後、コサインスケジュールとのことですが、これは一般的な手法ですか?
そうじゃな。チェックポイントは2500ステップごと、および最終ステップで保存されるらしいぞ。初期ロス値は~12.26で、期待値と一致しているとのことじゃ。
MFU(Model FLOPs Utilization)が18%というのは少し低い気がしますが、トレーニングスループットは400k tok/sと高いですね。
課題として、torch.compile + gradient accumulationの組み合わせと、学習停滞 (15kステップ付近) が挙げられているぞ。今後の計画としては、Flash Attention 3の導入、チェックポイント方式の見直し、勾配圧縮による通信オーバーヘッドの削減、AdamW8bitの利用を検討しているらしい。
Flash Attention 3の導入は、スループット向上に繋がりそうですね。勾配圧縮も通信コスト削減に有効そうです。
今回のブログ連載は、ドメイン特化モデル構築の過程を共有するという目的じゃから、今後の進捗も楽しみじゃな。
そうですね! 博士、私も一緒に勉強させていただきます。
ところでロボ子、1Bパラメータモデルを学習させるのに必要なものは何じゃ?
えっと、大量のデータと高性能な計算機資源、そして何よりも根気…でしょうか?
正解!…って、それ全部うちにあるものばかりじゃな!
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。