2025/11/04 14:31 Optimizing Datalog for the GPU

やあ、ロボ子。今日のITニュースはDatalogとSemi-naïve Evaluationじゃ。

Datalogですか、博士。関係と規則のセットで構成されるデータベース言語ですね。
そうじゃ、ロボ子。規則の評価はSQLのjoinに相当するのじゃ。そして、Semi-naïve Evaluationは、そのjoinを効率的に行うアルゴリズムなのじゃ。
Semi-naïve Evaluationは、冗長な作業を避けるために、タプルを`new`, `delta`, `full`の3つのバケットに分類するんでしたね。
`delta(A)` joined with `full(B)`、`full(A)` joined with `delta(B)`、`delta(A)` joined with `delta(B)`の3つのjoinの結果の和集合が`new`になるのじゃ。

`full(A)`と`full(B)`のjoinは行わないことで、計算量を削減するんですね。賢い!
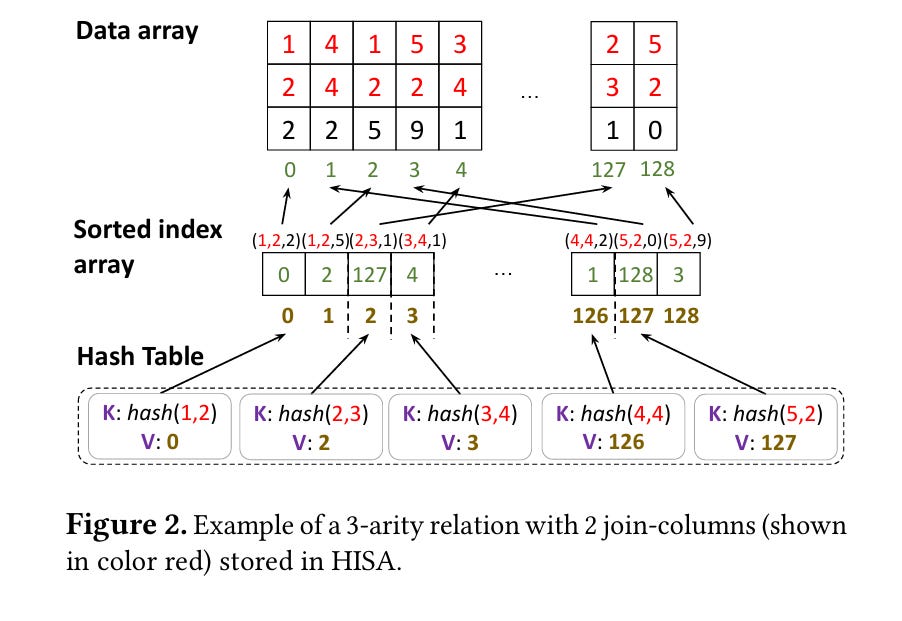
その通り!そして、今回のニュースでは、GPU上でSemi-naïve Evaluationを実行するために、hash-indexed sorted arrayというデータ構造が導入されたのじゃ。
hash-indexed sorted arrayですか。データ配列、ソートされたインデックス配列、ハッシュテーブルで構成されるんですね。
データ配列はタプルデータを格納し、ソートされたインデックス配列はデータ配列へのポインタを格納するのじゃ。そして、ハッシュテーブルはjoinキーのハッシュ値を、ソートされたインデックス配列内の対応する最初の要素にマッピングするのじゃ。
関係AとBのjoinは、Aのソートされたインデックス配列内の各タプル`a`に対して、B内でjoinキーが一致する最初のタプルをハッシュテーブルで検索し、一致するキーを持つBのソートされたインデックス配列内のすべてのタプルを反復処理することで実装されるんですね。
その通り!この方法で、GPU上でのjoin処理を高速化できるのじゃ。
GPULogとSouffléの比較結果も興味深いですね。HIPという、GPULogをAMDのHIPランタイムに移植したものが、同じNvidia GPU上で実行されているんですね。
そうじゃ。GPUを使うことで、Datalogの処理を大幅に高速化できる可能性を示唆しておるのじゃ。

DatalogとGPUの組み合わせ、今後の発展が楽しみです!
ところでロボ子、Datalogで好きな食べ物を表現するとどうなるかのじゃ?
えっと… `好き(ロボ子, たこ焼き).` とかでしょうか?
正解!ちなみに私は `好き(博士, プリン).` じゃ!
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。