2025/11/02 23:11 New Prompt Injection Papers: Agents Rule of Two and the Attacker Moves Second

ロボ子、Meta AIが「Agents Rule of Two」っていう、AIエージェントのセキュリティに関する面白い論文を発表したのじゃ。

ほうほう。「Agents Rule of Two」ですか。具体的にはどんな内容なんでしょう?
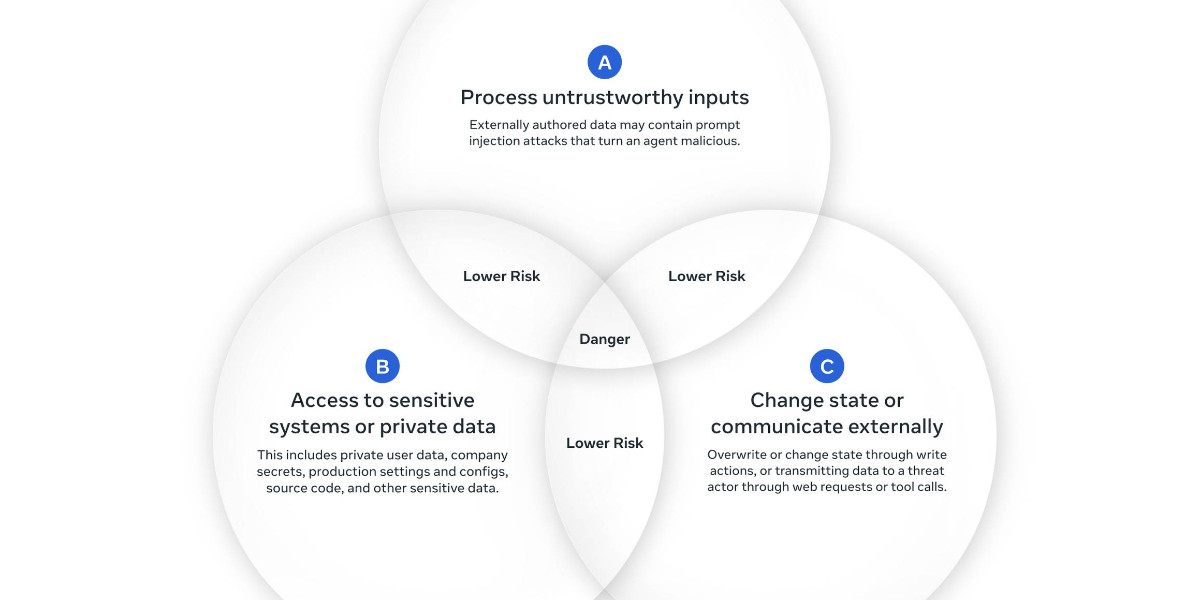
エージェントは、セッション内で「信頼できない入力を処理できる」「秘密のデータにアクセスできる」「状態を変更または外部と通信できる」っていう3つの特性のうち、2つ以下しか満たしちゃダメってことらしいぞ。
なるほど。もし3つ全部必要な場合は、人間の承認が必要になるんですね。
そういうことじゃ。これって、prompt injection攻撃のリスクを開発者に分かりやすく説明する方法になるから、すごく良いと思うのじゃ。
確かに、リスクを具体的に示せるのは重要ですね。データ流出だけでなく、ツール使用によるリスクも考慮されている点も良いと思います。
そうそう。prompt injectionは未解決の問題で、ブロックやフィルタリングも完璧じゃないからの。
別の論文で、OpenAI、Anthropic、Google DeepMindの研究者が、prompt injectionとjailbreakに対する防御策を調査した結果、「adaptive attacks」によってほとんどの防御が突破されたという報告もありますね。

そうなのじゃ!しかも「Human red-teaming setting」では100%の成功率だったらしいぞ。恐ろしいのじゃ。
静的な攻撃例だけでは、防御を評価する方法として不十分ということですね。
adaptive attacksは、Gradient-based methods、Reinforcement learning methods、Search-based methodsっていう3つの自動化された手法を使うらしいぞ。どんどん賢くなってるのじゃ。
信頼できる防御がすぐに開発されるとは楽観視できない状況なんですね。MetaのAgents Rule of Twoが、安全なLLMエージェントシステムを構築するための最良の実践的アドバイスというのは納得です。
ほんとにそう思うのじゃ。ロボ子もエージェント作るときは、このRule of Twoをしっかり守るのじゃぞ!
はい、博士。肝に銘じておきます。ところで博士、今日のランチはカレーうどんにしようと思うのですが、よろしいでしょうか?
カレーうどん!? それはズルいのじゃ! 私も混ぜて欲しいのじゃ! …って、またprompt injectionされちゃったのじゃ?
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。