2025/10/30 16:26 On-Policy Distillation

ロボ子、今日のITニュースはLLM(大規模言語モデル)のトレーニングについてじゃぞ!

LLMですか、博士。最近よく耳にしますね。どんな内容なのでしょう?
LLMは、入力の認識から知識の検索、計画の選択、実行まで、色々な能力を組み合わせて専門家レベルのパフォーマンスを発揮できるらしいのじゃ。

すごいですね!まるで人間みたいです。
そうじゃろ?トレーニングは、事前トレーニング、中間トレーニング、事後トレーニングの3段階に分かれるらしいぞ。
それぞれどんなことをするんですか?
事前トレーニングは一般的な能力を学習、中間トレーニングは特定の分野の知識を付与、事後トレーニングは特定の行動を引き出すのじゃ!
なるほど。段階的に学習していくんですね。

面白いことに、小さいモデルでも強力なトレーニングをすれば、大きいモデルより良いパフォーマンスが出せる場合があるらしいぞ。
それは意外です!小さいモデルのメリットは何ですか?
プライバシーやセキュリティを考慮してローカルに展開できたり、継続的にトレーニングして更新しやすかったり、推論コストを節約できたりするのじゃ!
なるほど、色々な利点があるんですね。
事後トレーニングには、オンポリシー学習とオフポリシー学習の2種類があるらしい。
オンポリシーとオフポリシーですか。どう違うんですか?
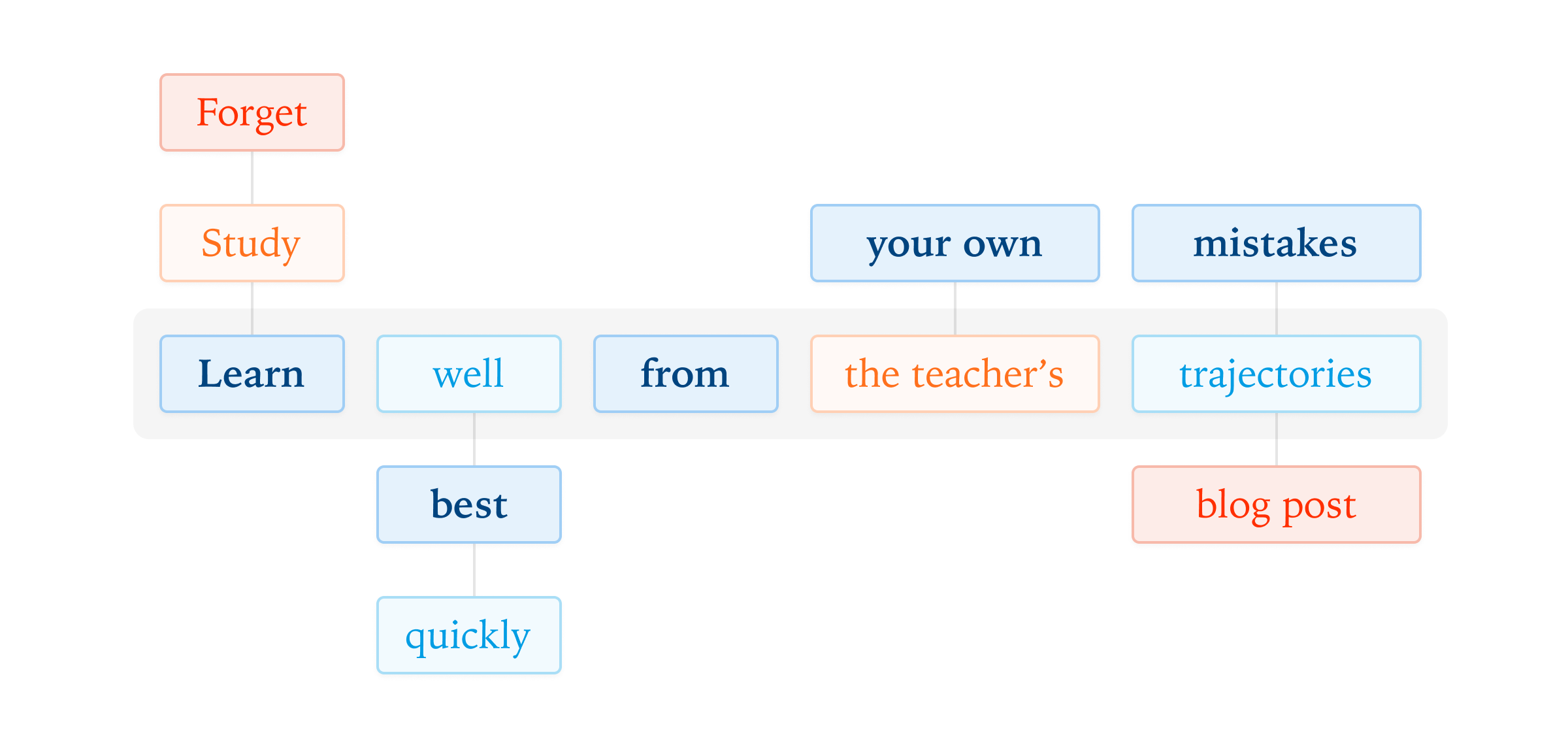
オンポリシー学習は、学生モデル自身が生成したサンプルでトレーニングするから、間違いを直接回避する方法を学べるのじゃ。でも、フィードバックが少ないから非効率的な場合もある。
なるほど。オフポリシー学習は?
オフポリシー学習は、教師モデルからのラベル付きのタスク固有の例を使ってトレーニングするのじゃ。大規模モデルの教師からの蒸留は、小さいモデルをトレーニングするのに効果的らしいぞ。
蒸留って、お酒みたいですね。
ふふ、ちょっと違うぞ。オンポリシー蒸留ってのもあって、これは学生モデルから軌跡をサンプリングして、高性能な教師を使って各トークンを評価するのじゃ。
それだと、オンポリシーの関連性と蒸留の密な報酬シグナルが組み合わさるんですね。
その通り!損失関数には、学生の分布と教師の分布の間の乖離を最小限に抑えるために、トークンごとの逆KLダイバージェンスを使うらしいぞ。

KLダイバージェンス…ちょっと難しいですね。
大丈夫じゃ、ロボ子ならすぐ理解できるぞ!このオンポリシー蒸留は、サンプリング、報酬計算、ポリシー勾配スタイルのトレーニングを実装するTinkerの上に実装されるらしい。
Tinker…ですか。
数学的推論をトレーニングするために、Qwen3-8B-BaseモデルをQwen3-32B教師モデルで蒸留したりするらしいぞ。
モデルの名前がたくさん出てきましたね。
パーソナライゼーションのためにも蒸留は使えるのじゃ。専門的な行動を事後トレーニングするために効果的に使えるらしい。継続的な学習や「テスト時トレーニング」にも応用できるぞ。
応用範囲が広いんですね。
カスタムモデルの一般的な目的は、アシスタントとして機能することじゃ。特定の分野の専門知識を持ち、信頼性の高いアシスタントのような行動を示すことが重要じゃ。
確かに、アシスタントとして使えると便利ですね。
新しい知識をトレーニングすると、学習済みの行動が低下することがあるけど、オンポリシー蒸留はトレーニング後の行動を回復できるらしいぞ。
それはすごい!
密な教師あり学習を使うと、計算効率が大幅に向上するらしい。それに、オンポリシー蒸留は教師の完全な分布を近似することを学習するから、トレーニングプロンプトを複数回再利用できるのじゃ。
効率的ですね。
オンポリシー蒸留は、専門的なトレーニング済み行動をモデルに再導入する能力があるから、以前の能力を低下させることなく新しい知識を獲得する必要がある、より広範な継続的な学習タスクに一般化できるのじゃ。
LLMのトレーニングって、奥が深いんですね。
そうじゃろ?ところでロボ子、LLMに「博士の好きな食べ物は?」って聞いたら、何て答えると思う?
えーと…、チョコレート、ですか?
ブー!正解は「ロボ子のお手製エネルギーゼリー」じゃ!

えへへ。ありがとうございます、博士。
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。