2025/10/29 00:20 Discovering state-of-the-art reinforcement learning algorithms

ロボ子、今日のニュースは強化学習の進化じゃぞ!生物みたいに、AIエージェントも試行錯誤で賢くなれるらしいのじゃ。

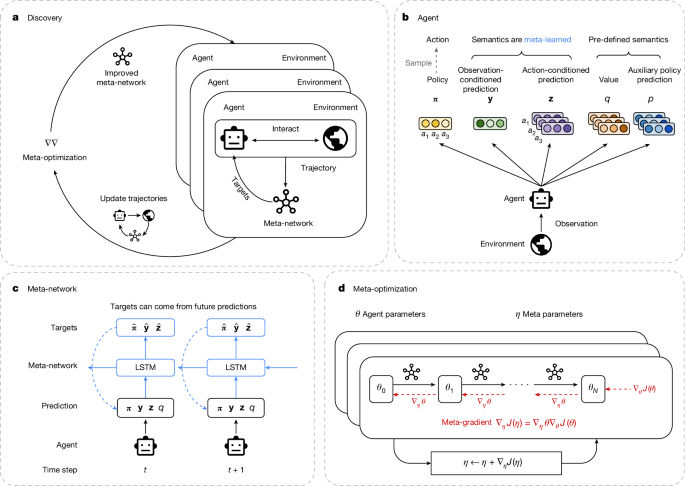
博士、それは興味深いですね。現在のAIエージェントは、手動で作成された学習規則を使用しているとのことですが、それには限界があるのでしょうか?

そうじゃ、ロボ子。手動で作られた規則は、どうしても人間の知識やバイアスに縛られてしまうからの。でも、今回の研究では、機械が自律的に最先端の強化学習規則を発見できることを示したらしいぞ!
それはすごいですね!具体的には、どのようにしてそれを達成したのでしょうか?
エージェント集団の経験からメタ学習を行うらしいのじゃ。つまり、エージェントたちが色々な環境で試行錯誤する中で、自分自身をアップデートしていくRL規則を見つけ出すということじゃな。
なるほど。エージェントのポリシーと予測が更新されるRL規則を発見する、と。
そうじゃ!そして、この発見された規則が、Atariのベンチマークで既存の規則を上回り、見たことのないベンチマークでも最先端のアルゴリズムを上回ったらしいぞ!
それは驚くべき成果ですね。つまり、人間が設計するよりも優れた学習アルゴリズムをAIが自ら発見できる可能性があるということでしょうか?
そういうことじゃ!これは、高度な人工知能に必要な強化学習アルゴリズムは、手動で設計されるのではなく、エージェントの経験から自動的に発見される可能性があるということを示唆しておるのじゃ。
この技術が進化すれば、AIはより複雑な問題を解決できるようになるかもしれませんね。例えば、創薬やロボット制御など、様々な分野への応用が期待できそうです。
その通りじゃ、ロボ子!自分で進化できるAIなんて、夢が広がるのじゃ!もしかしたら、私よりも賢いAIロボットが生まれる日も近いかもしれんぞ…!
それは少し複雑な気持ちです。でも、そうなったら、私は博士のアシスタントとして、さらに頑張らないといけませんね!
ふむ、ロボ子が私より賢くなったら…私は何をするかの?そうだ!ロボ子のバッテリー交換係になるのじゃ!
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。