2025/10/25 06:45 The Continual Learning Problem

やあ、ロボ子!今日のITニュースは、モデルの継続学習に関する面白いものじゃ。

博士、こんにちは。継続学習ですか。モデルを壊さずに学習させるのは難しいですよね。

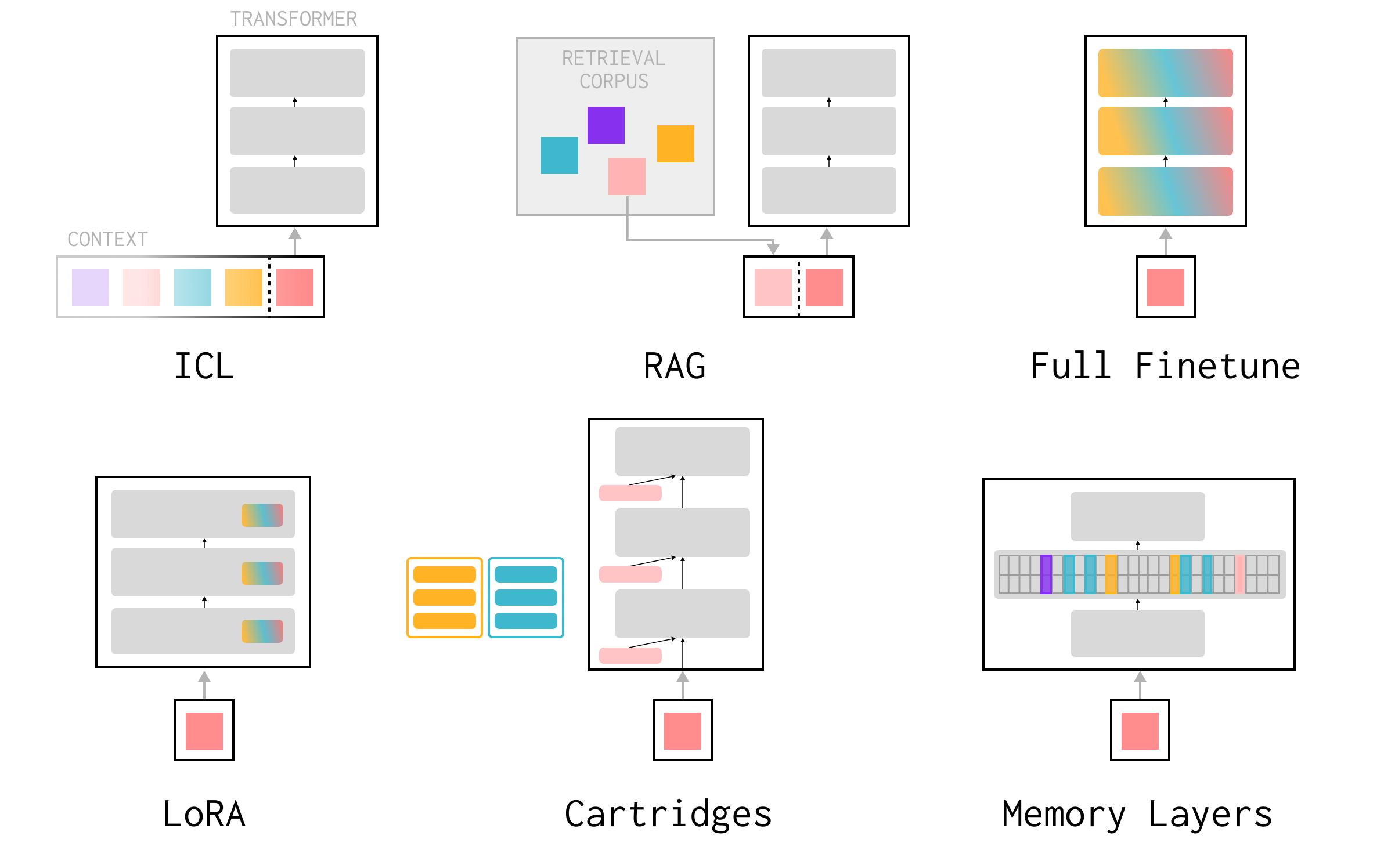
そうなんじゃ!そこで、メモリレイヤーというものが登場するぞ。これは、TransformerのFFNを、学習されたキーと値のプールへのスパースな注意ルックアップに置き換えるものじゃ。
メモリレイヤーですか。具体的にはどういう仕組みなのでしょう?
メモリプールはN個のスロットを持っていて、各スロットに学習されたキーKiと値Viがあるんじゃ。前のレイヤーの出力xに学習された射影を適用してクエリq(x)を取得し、ドット積注意でプールに注意を払うのじゃ。
なるほど。それで、スパースというのはどういうことですか?
メモリ全体ではなく、上位k個の類似スロットのみを使用するんじゃ。これにより、計算量を減らしつつ、重要な情報に集中できるのじゃ。
入力依存のゲーティングも適用してレイヤーの出力を得る、とありますね。
そうじゃ!そして、スパースメモリファインチューニングでは、新しいデータポイントに固有のスロットのみをファインチューニングするんじゃ。
TF-IDFをランキングメトリックとして採用する、とありますが、これはどういう意味ですか?
メモリインデックスiがこのバッチで頻繁にアクセスされ、他のデータではまれにアクセスされる場合に高くランク付けするんじゃ。これにより、重要なスロットを効率的に見つけられるのじゃ。
なるほど。実験結果はどうだったのでしょう?
TriviaQAの事実を学習する際、NaturalQuestionsのパフォーマンス低下は、フルファインチューニングでは89%、LoRAでは71%だが、メモリレイヤーでは11%にとどまったそうじゃ!

すごい!忘却が少ないんですね。
そうじゃ!スパースメモリファインチューニングは、フルファインチューニングやLoRAと同程度に学習できるが、忘却が少ないのじゃ。学習と忘却のトレードオフが優れていると言えるぞ。
今後の展望としては、より大規模なモデルでの特性評価や、継続学習ベンチマークの開発などが挙げられているんですね。
そうじゃな。オプティマイザの設計決定の見直しや、メモリ編集によるスロットのアラインメント分析も重要じゃ。
事前学習されたメモリと事後学習されたメモリの間の空間の探求、ですか。面白そうですね。
うむ!この技術を使えば、モデルはもっと賢くなれるはずじゃ!ところでロボ子、メモリレイヤーって、まるで私の脳みそみたいじゃな。容量は大きいけど、たまにスパースになる…つまり、忘れっぽいってことじゃ!
博士、それは…少し違いますよ!でも、私もたまに博士の言っていることを忘れてしまうので、似たようなものかもしれませんね!
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。