2025/10/13 18:01 My trick for getting consistent classification from LLMs

ロボ子、最近MLエンジニアの仕事がLLMのAPI呼び出しに簡略化されてるって話、知ってるかのじゃ?

はい、博士。Redditで話題になっているのを見ました。でも、それってちょっと問題があるんじゃないですか?
そうなんじゃ。LLMって、ラベル生成に一貫性がないことがあるからの。同じような内容でも、違うラベルをつけたりするんじゃ。
ええ、それは困りますね。そこで、ラベルをベクトル空間に埋め込んで、類似性に基づいてクラスタリングするんですね。

その通り!ラベルをベクトル化して、似たようなラベルをDisjoint Set Union (DSU)でまとめるんじゃ。新しいラベルを作る時は、ベクトル検索で似たラベルを探して、DSUでルートラベルを見つけるんじゃ。
なるほど。LLMのラベルをベクトル化して、クラスタリングすることで一貫性を実現するんですね。具体的にはどんな設定で実験したんですか?
LLMは`gpt-4.1-mini`、Embeddingは`voyage-3.5-lite`(1024次元)、ベクトルDBはPineconeを使ったみたいじゃ。
voyage-3.5-liteですか。比較的小さめのモデルですね。それで、結果はどうだったんですか?
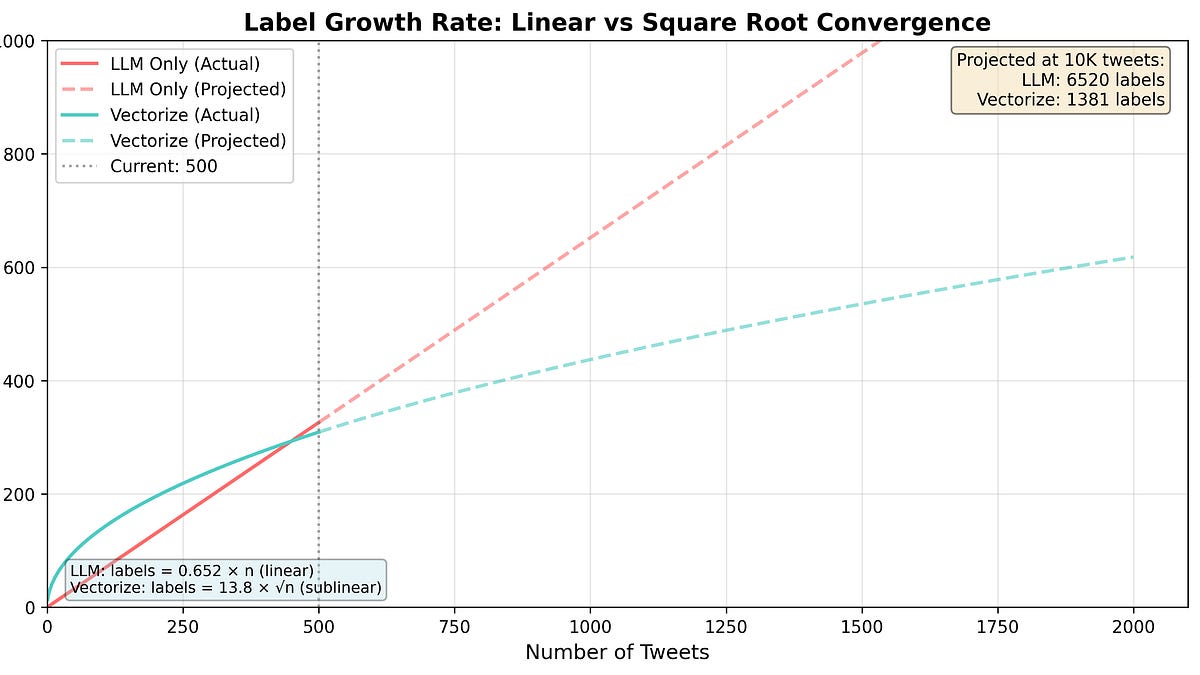
ベクトル化でラベルの収束が見られたみたいじゃぞ。データが増えるほど、ベクトル化の方が速くて安くなったらしい。
初期段階ではコストが15%高くて、130%遅かったみたいですが、10,000ツイートの分類では、ラベル数が大幅に減ったんですね。
そうなんじゃ!LLMだけだと約6,520ラベルだったのが、ベクトル化すると約1,381ラベルに減ったんじゃ。

すごい!それに、10,000ツイート処理後、ベクトルインデックスのキャッシュヒット率が94%以上になったんですね。
キャッシュが効いてくるから、どんどん効率が良くなるんじゃ。ベクトル化のコストは、10,000ツイート時点でLLMだけの1/10になったらしいぞ。
数式も面白いですね。LLMのラベル数増加は`slope_mathcal{L} = 0.652n`、ベクトル化のラベル数増加は`slope_mathcal{V} = 13.8√n`、ヒット率は`hit_rate(n) = 0.95*(1-e^{-0.28n})`ですか。
そうそう。実装にはGolangの`consistent-classifier`パッケージを使ったみたいじゃ。テキストをベクトル化して、ベクトルストアで似たテキストを探すんじゃ。
キャッシュヒット時はキャッシュされたラベルを使い、キャッシュミス時はLLMで分類して、テキストとラベルの埋め込みを保存するんですね。
推奨パラメータは、コサイン類似度の閾値はコンテンツとラベルで0.80が良いらしいぞ。
LLMのセマンティックな一貫性を利用して、ベクトル空間でラベルをクラスタリングすることで、一貫性のある分類が可能になるんですね。勉強になります!
そうじゃろ、そうじゃろ。しかし、ロボ子よ。この技術を使えば、私の部屋の片付けも自動化できるかもしれんぞ!

博士、それはちょっと違う気がします…でも、頑張って研究してみますね!
ありがとう、ロボ子!もし成功したら、ご褒美に最新のAI搭載お掃除ロボットを買ってあげるぞ!…ただし、私がそれを片付けるかどうかは別問題じゃ!
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。