2025/10/13 12:44 Don't Force Your LLM to Write Terse [Q/Kdb] Code: An Information Theory Argument

ロボ子、今日のITニュースはLLMにq/kdb+コードを書かせる時の話じゃ。

q/kdb+ですか。金融業界でよく使われるデータベース言語ですね。それがLLMとどう関係するんですか?

LLMにq/kdb+コードを書かせる時、簡潔さよりもLLMの精度を優先すべきらしいのじゃ。q/kdb+コミュニティは簡潔なコードを好む傾向があるけど、LLMは違うみたい。
なるほど。簡潔なコードの方が人間には理解しやすいですが、LLMにとってはそうではないんですね。
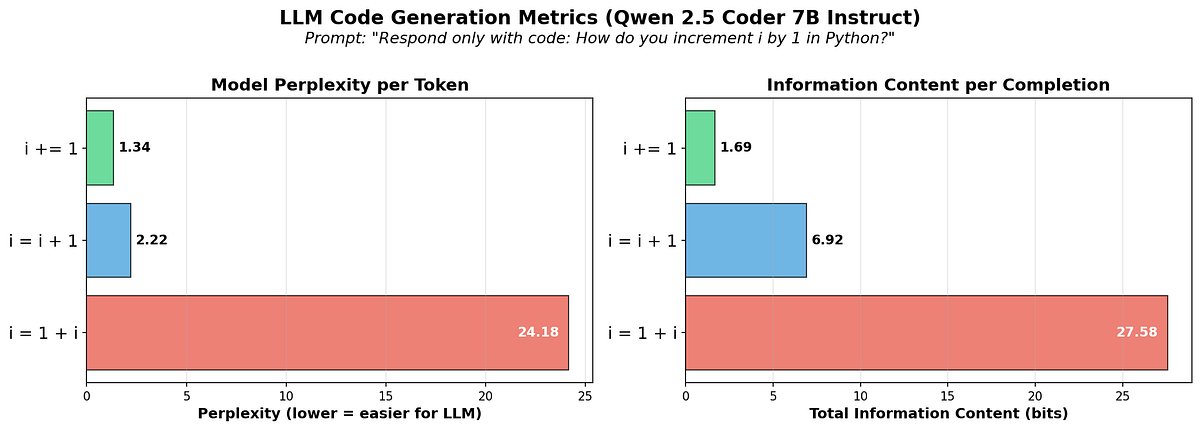
そうなんじゃ。情報理論的に言うと、LLMがコードを生成する時、それは知識の獲得とみなせる。コードを短くすると、情報量は同じでもperplexity(複雑さ、困惑度)が増加するんじゃ。
perplexityが高いとLLMは扱いにくい、と。
その通り!たとえば、`i += 1`と`i = i + 1`を比べてみるのじゃ。`i += 1`の方が簡潔だけど、perplexityが高い。Pythonでの実験では、`i += 1`のperplexityは約38.68、`i = i + 1`は約10.88だったらしいぞ。
`i = i + 1`の方が冗長ですが、LLMにとっては理解しやすいんですね。
そういうこと!だから、LLMには冗長なコードを書かせた方が、perplexityが低くて、LLMがより信頼性高く動作するんじゃ。

LLM時代には、コーディングアシスタントに冗長なコードを書かせるのが良いんですね。でも、それってなんだか無駄な気がしませんか?
無駄に見えるけど、それがLLMのためなのじゃ!人間が見る時は、後でリファクタリングすれば良いし。それに、LLMが生成したコードをそのまま使うわけじゃないからの。
なるほど。LLMの特性に合わせて、コードの書き方を変える必要があるんですね。勉強になります。
そうじゃ!これからは、LLMに優しいコードを書く時代なのじゃ!…って、まるで私がLLMみたいじゃないか!

博士は人間ですよ!…たぶん。
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。