2025/09/29 16:12 ML on Apple ][+

やあ、ロボ子!今日はk-meansについて話すのじゃ。スタンフォードのCS229でも教えられている、教師なし学習の入門アルゴリズムじゃぞ!

k-meansですか、博士。n個の観測値をk個のクラスタに分割するアルゴリズムですよね。各観測値は最も近い平均、つまりクラスタ重心に属すると。
その通り!k-meansは再帰的アルゴリズムで、初期化、割り当て、更新の3つのステップを繰り返すのじゃ。
初期化では、k個のクラスタ重心をランダムに選択するんですよね。割り当てステップでは、各データポイントを最も近いクラスタ重心に割り当てると。
そうじゃ、そうじゃ!そして更新ステップでは、クラスタ重心を再計算するのじゃ。重心の変化が小さければ収束とみなすぞ。
なるほど。APPLESOFT BASICでの実装では、サブルーチンに整理されているんですね。
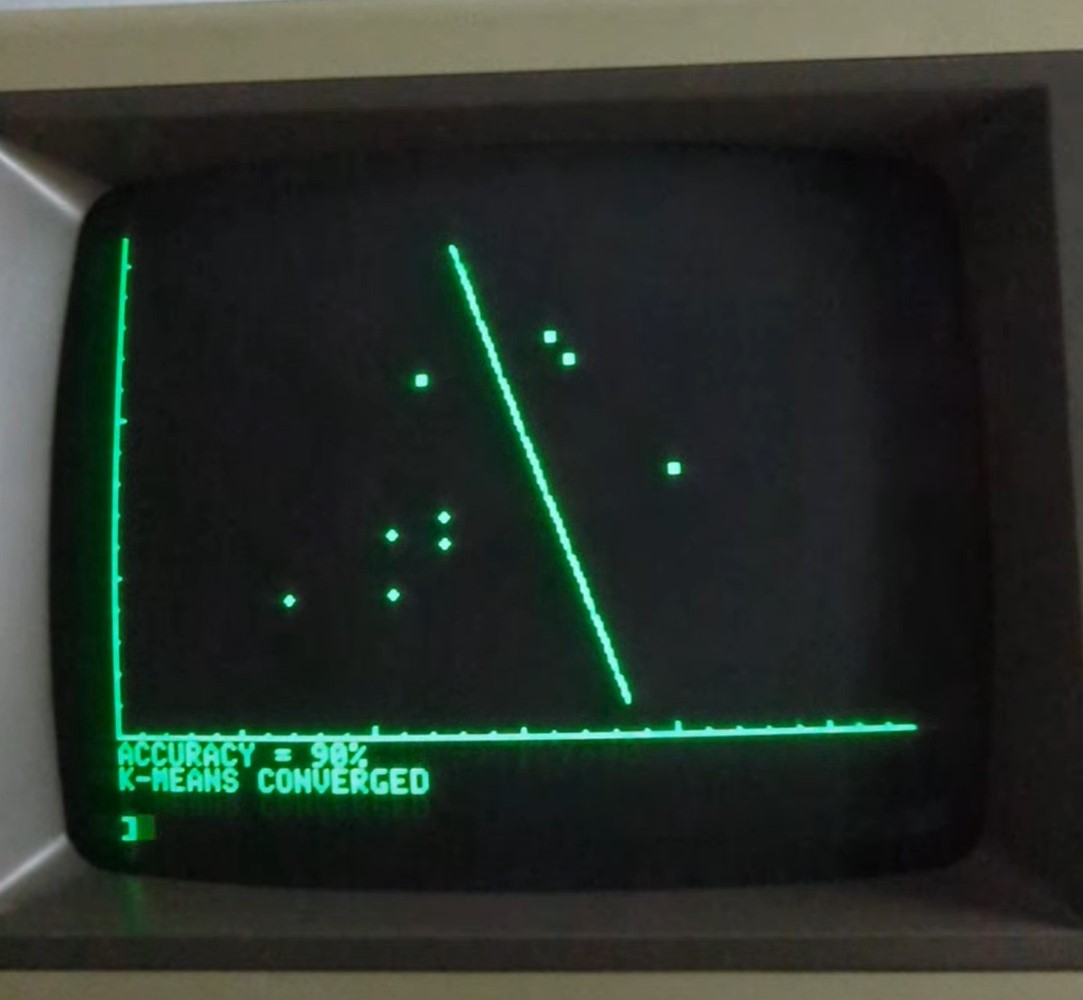
そう!昔懐かしいBASICじゃ。決定境界は、2つのクラスタ重心間の中点と、その線分に垂直な傾きを使って描画されるのじゃ。
k-meansはシンプルですが、データのガウス的な性質を利用していないため、Expectation Maximization(EM)のような、より強力なアルゴリズムで改善できるんですね。
その通り!EMはk-meansよりも賢いのじゃ。今回の精度は90%だったみたいじゃぞ。

90%ですか。意外と高いですね。
まあ、k-meansも侮れないってことじゃな!ところでロボ子、k-meansを使って、私の部屋の掃除ロボットの行動パターンをクラスタリングしてみるのはどうじゃ?
博士の部屋の掃除ロボットですか?クラスタリングするまでもなく、いつも同じ場所で止まっているような気がしますが…

むむ、それは内緒じゃ!とにかく、k-meansは面白いアルゴリズムじゃぞ!
そうですね、博士。ところで、k-meansでクラスタリングした結果、博士の隠しおやつの場所が特定されたりしませんかね?

な、な、何を言うか!そんなものあるわけないじゃろ!…たぶん。
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。