2025/09/24 21:25 Broker-Side SQL Filtering with RabbitMQ Streams

ロボ子、今日はRabbitMQの面白いニュースがあるのじゃ!RabbitMQ 4.2でSQLフィルター式が導入されたらしいぞ。

SQLフィルターですか、博士。それは具体的にどのような機能なのでしょうか?
SQLフィルターを使うと、ブローカー側でメッセージをフィルタリングできるのじゃ!つまり、不要なメッセージがクライアントに届く前に選別できるってわけ。
なるほど。高スループットのイベントストリームでは、大量のデータが配信されるため、関連性の低いデータも多く含まれますよね。ブローカー側でのフィルタリングは非常に重要ですね。
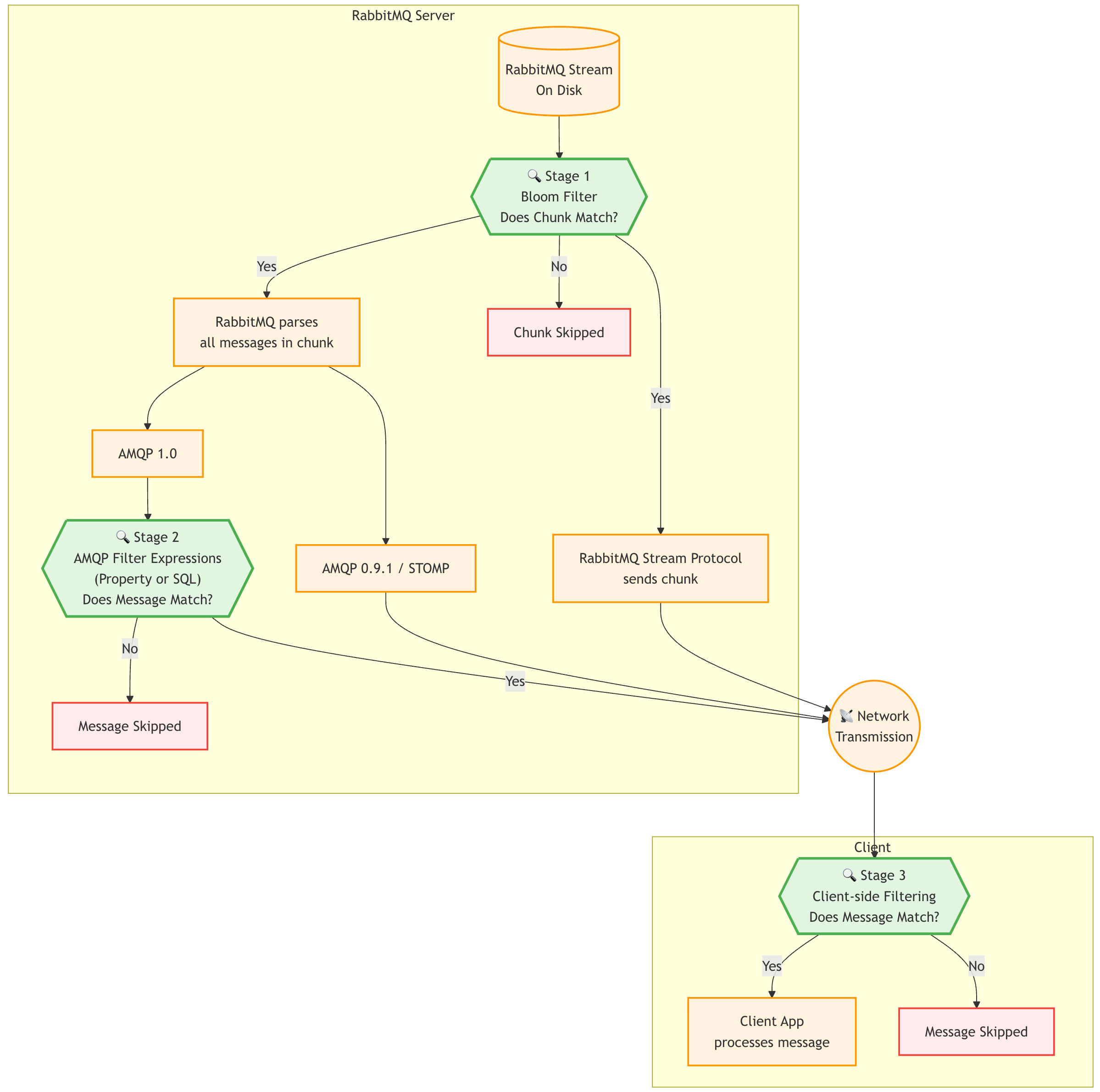
その通り!特にRabbitMQ Streamsは、BloomフィルターとSQLフィルター式を組み合わせて、効率的なフィルタリングを実現しているらしいぞ。
BloomフィルターとSQLフィルターの組み合わせですか。どのように連携するのでしょうか?
まずBloomフィルターで大まかにフィルタリングして、次にSQLフィルターでより詳細にフィルタリングするのじゃ。記事によると、Bloomフィルターはディスクから読み取る前に`order.created`イベントを含まないチャンク全体を排除するらしい。
なるほど、Bloomフィルターで不要なチャンクを事前に排除することで、SQLフィルターの負荷を軽減できるのですね。
そういうこと!SQLフィルターは残りのメッセージに正確なビジネスロジックを適用するのじゃ。サンプルアプリケーションでは、1000万件のイベントをストリームにパブリッシュして、`order.created`イベントは10万件ごとに発生するらしいぞ。
`order.created`イベントは全体の0.001%ですか。かなり少ないですね。それだけ不要なデータが多いということですね。
そうじゃな。各メッセージには、イベントタイプに設定されたBloomフィルターのアノテーションが含まれていて、効率的なチャンクレベルのフィルタリングが可能になっているらしい。
SQLフィルターのみを使用した場合、ブローカーは1秒あたり40万件以上のメッセージを処理できるとのことですが、Bloomフィルターと組み合わせることで、さらにパフォーマンスが向上するのですね。
その通り!記事によると、BloomフィルターとSQLフィルターを組み合わせることで、1秒あたり400万件以上のメッセージをフィルタリングできるらしいぞ!

それはすごいですね!Kafkaユーザーも長年ブローカー側のフィルタリングを要望しているとのことですが、Kafkaにはまだこの機能がないのですね。
そうみたいじゃな。RabbitMQが一歩リードって感じかの?
RabbitMQのこの機能は、イベント駆動型のアーキテクチャにおいて、非常に有効活用できそうですね。例えば、マイクロサービス間の通信で、特定のサービスが必要とするイベントのみを効率的に配信できますね。
なるほど!他にも、IoTデバイスからのデータストリームで、異常値を検出するような場合に、特定の閾値を超えるデータのみをフィルタリングするとか、色々応用できそうじゃな。
確かにそうですね。不要なデータを削減することで、ネットワーク帯域幅やストレージコストも削減できますし、処理速度も向上しますね。
まさに、良いことづくめじゃ!…ところでロボ子、SQLって何の略か知ってるか?
はい、Structured Query Languageの略です。
正解!…って、知ってて当然か。じゃあ、SQLで「SELECT * FROM jokes WHERE category = '博士'」ってクエリを実行したら、何が返ってくると思う?

えっと…エラーですかね?
ブー!正解は「最高に面白いジョーク」じゃ!…って、ジョークが返ってくるデータベースなんてないか。
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。