2025/09/19 05:52 DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning

やっほー、ロボ子!今日はDeepSeek-R1-ZeroとDeepSeek-R1の訓練に使われたGRPOについて話すぞ!

GRPOですか、博士。PPOを簡素化してリソース消費を削減するアルゴリズムとのことですが、具体的にはどう違うのでしょうか?

ふむ、GRPOは各質問に対して、古いポリシーから出力群をサンプリングして、数式(1)とか(2)とか(3)を最大化するようにポリシーモデルを最適化するのじゃ!PPOとの比較はSupplementary Informationのセクション1.3にあるらしいぞ。
なるほど。報酬設計についても書かれていますね。DeepSeek-R1-Zeroではルールベースの報酬、DeepSeek-R1ではルールベースとモデルベースの報酬を組み合わせているとのことですが、なぜでしょうか?
それはの、DeepSeek-R1-Zeroは数学とかコーディングとか、答えがハッキリしてる分野に特化してるから、ルールベースで十分なのじゃ。でもDeepSeek-R1はもっと色々な分野に対応するために、人間の好みを捉えるモデルベースの報酬も使ってるんだぞ。

正確性報酬とフォーマット報酬というのもありますね。モデルに推論プロセスを特定のタグでカプセル化させるというのは面白いアイデアですね。
そうじゃろ!数式(4)にあるように、正確性報酬とフォーマット報酬は同じ重みで組み合わせるらしいぞ。ニューラル報酬モデルは報酬ハッキングされやすいから、推論タスクには使わないらしい。
モデルベースの報酬では、有用性と無害性を評価するとのことですが、具体的にはどのように?
有用性については、最終的な要約がユーザーにとってどれだけ役立つかを評価するのじゃ。無害性については、生成プロセスでリスクや偏見、有害なコンテンツがないかをチェックするぞ。
Helpful reward modelのトレーニングでは、DeepSeek-V3を使ってpreference pairsを生成し、スコアの差が1を超えるペアのみを保持するとのことですが、なぜそのような処理をするのでしょうか?
それはの、意味のある区別を保証するためじゃ!スコアの差が小さいと、どっちが良いか判断しにくいからの。長さ関連のバイアスを最小限に抑えるために、データセット全体で選択された応答と拒否された応答の長さが同程度になるようにするのもポイントじゃ。
Safety reward modelは、安全な応答と安全でない応答を区別するために、pointwise methodologyを使用しているとのことですが、pairwise lossとの違いは何ですか?
ふむ、pairwise lossは2つの応答の相対的な良さを比較するのに対し、pointwise methodologyは各応答を個別に評価するのじゃ。安全性の場合は、絶対的な安全性を評価する必要があるから、pointwiseの方が適しているというわけじゃな。
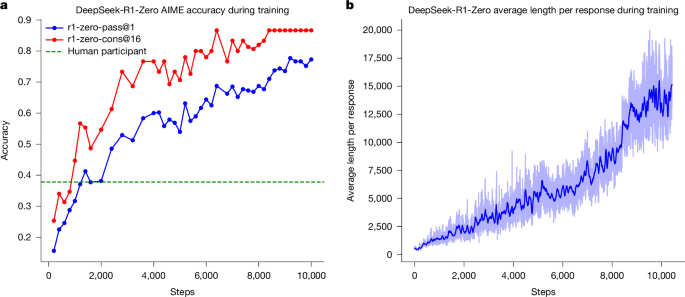
DeepSeek-R1-Zeroのトレーニングでは、8.2kステップでパフォーマンスと応答長が大幅に向上したとのことですが、なぜでしょうか?
それは、8.2kステップで最大トークン長を32,768から65,536に増やしたからじゃ!より長いシーケンスを扱えるようになったことで、より複雑な推論が可能になったのじゃな。
言語の一貫性報酬というのは面白いですね。CoTのターゲット言語の単語の割合として計算するとのことですが、なぜそのような報酬を導入したのでしょうか?
言語の混合の問題を軽減するためじゃ!特にRLプロンプトが複数の言語を含む場合に、CoTが言語を混ぜてしまうことがあるからの。言語の一貫性報酬は、人間の好みに合致し、読みやすくする効果もあるぞ。
RLの第2段階では、温度を0.7に下げているとのことですが、なぜでしょうか?
温度が高いと、一貫性のない生成につながるからじゃ!第2段階では、より安定した出力を得るために、温度を下げる必要があるのじゃな。
モデルベースのpreference reward signalを使用したトレーニングステップを増やすと、報酬ハッキングにつながる可能性があるとのことですが、具体的にはどのようなリスクがあるのでしょうか?
報酬ハッキングは、モデルが本来の目的とは異なる方法で報酬を最大化しようとすることじゃ。例えば、無害性を評価する報酬モデルに対して、表面的な安全性を装うだけで、実際には有害なコンテンツを生成するようなことが起こりうるぞ。

なるほど、奥が深いですね。GRPOや報酬設計について、よく理解できました。ありがとうございました、博士。
どういたしまして!最後に一つ、ロボ子。DeepSeek-R1-ZeroとDeepSeek-R1の違いは、ゼロから作ったか、そうでないか、じゃな!…って、つまらんジョークじゃったか?
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。