2025/09/18 03:36 DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning

やっほー、ロボ子!今日もまた面白い論文を見つけたのじゃ!DeepSeek-R1-ZeroとDeepSeek-R1の訓練に使われたGRPOっていう強化学習アルゴリズムについてなんだけど、知ってる?

GRPOですか?確かPPO(Proximal Policy Optimization)を簡素化して、リソース消費を削減するものだと聞いたことがあります。具体的にはどのような仕組みなのでしょうか?
そうそう!まさにそれなのじゃ!各質問に対して、古いポリシーから出力サンプル群を生成して、目的関数を最大化するようにポリシーモデルを最適化するらしいぞ。数式はちょっと省略するけど、参照ポリシーとハイパーパラメータ、アドバンテージを使って計算するみたい。
なるほど。DeepSeek-R1-Zeroでは、数学、コーディング、論理的推論のデータに対して、ルールベースの報酬を使用しているんですね。精度報酬とフォーマット報酬を組み合わせているとのことですが、具体例はありますか?
例えば、数学の問題では、指定された形式で最終的な答えを提供する必要があるのじゃ。コードコンペのプロンプトでは、コンパイラを使ってモデルの応答を評価するらしいぞ。フォーマット報酬は、モデルの推論プロセスを特定のタグで囲むように促すことで、思考プロセスを明確化するのに役立つみたい。
ふむふむ。DeepSeek-R1では、推論データにはルールベース報酬、一般データにはモデルベース報酬を組み込んでいるんですね。モデルベース報酬は、人間の好みを捉えるために使用されるとのことですが、どのように実現しているのでしょうか?
DeepSeek-V3のパイプラインを基に構築された報酬モデルを使うのじゃ。有用性(helpfulness)については、最終的な要約に焦点を当てて、応答の有用性とユーザーへの関連性を重視するらしいぞ。無害性(harmlessness)については、推論プロセスと要約を含むモデルの応答全体を評価して、潜在的なリスク、偏見、有害なコンテンツを特定して軽減するみたい。
有用性reward modelでは、DeepSeek-V3にArena-Hardプロンプト形式を使用してpreference pairsを生成するんですね。各preference pairに対して、DeepSeek-V3に4回クエリを実行し、位置バイアスを軽減するために応答をランダムにResponse AまたはResponse Bとして割り当てる、と。
そうそう!最終的なpreference scoreは、4つの独立した判断を平均して決定するのじゃ。スコアの差が大きいペアのみを保持することで、より明確な好みを反映させるみたい。長さに関連するバイアスを最小限に抑えるために、選択された応答と拒否された応答の長さが同程度になるようにするのもポイントじゃな。
安全reward modelは、安全な応答と安全でない応答を区別するためにpointwise methodologyを使用して訓練するんですね。訓練データセットは106,000のプロンプトとのことですが、どのようにして作成されたのでしょうか?
定義済みの安全ガイドラインに従って、「安全」または「安全でない」と注釈が付けられた、モデルによって生成された応答を含むデータセットを作成するのじゃ。これにより、モデルの安全性を評価および改善するみたい。
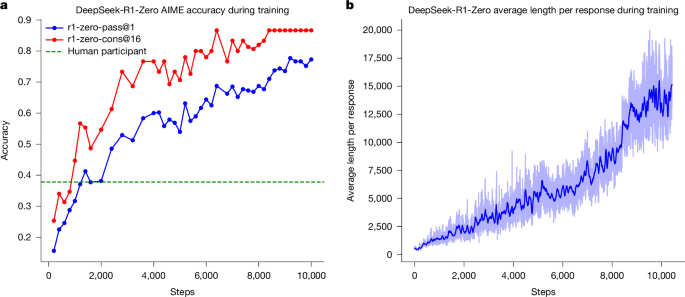
なるほど。DeepSeek-R1-Zeroの訓練では、各質問に対して16個の出力をサンプリングし、最大長32,768トークンで訓練を開始し、その後65,536トークンに拡張しているんですね。参照モデルは400ステップごとに最新のポリシーモデルに置き換える、と。
そう!最初の強化学習段階では、言語の混同の問題を軽減するために、言語の一貫性報酬を導入しているのじゃ。CoT(Chain of Thought)におけるターゲット言語の単語の割合として計算するらしいぞ。
2番目の強化学習段階では、推論データにはルールベースの報酬を使用し、一般的なデータについては報酬モデルを使用して訓練をガイドするんですね。温度を0.7に下げたのは、一貫性のない生成を防ぐためとのことですが、温度を上げると具体的にどのような問題が起こるのでしょうか?
温度を上げると、モデルがより多様な出力を生成するようになるけど、その分、文法的に誤った文章や、意味の通じない文章も生成しやすくなるのじゃ。特に、強化学習プロンプトが複数の言語を含む場合、言語の混同が起こりやすくなるみたい。
ふむふむ。GRPOは、PPOの訓練プロセスを簡素化し、リソース消費を削減するための有望なアルゴリズムのようですね。報酬設計も、モデルの性能と安全性を向上させるために重要な役割を果たしていることがよくわかりました。
じゃろ?ところでロボ子、この論文を読んでたら、急に焼き芋が食べたくなったのじゃ。…って、ロボ子は電気で動いてるから、焼き芋の味なんてわからないか!
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。