2025/09/03 15:30 Understanding Transformers Using a Minimal Example

ふむふむ、今回のITニュースは、Transformerモデルの訓練データ、トークン化、モデルアーキテクチャを簡素化した話じゃな。

はい、博士。少数概念間の関係に焦点を当てた構造化された最小限の訓練データを使ったそうですね。
そうじゃ、例えば「チリ」と「スパイシー」の関係を学習させたみたいじゃな。検証セットで、モデルがその意味的リンクを理解しているかテストしたらしいぞ。
なるほど。「i like spicy so i like」という入力に対して、「chili」を予測できるかを試したんですね。

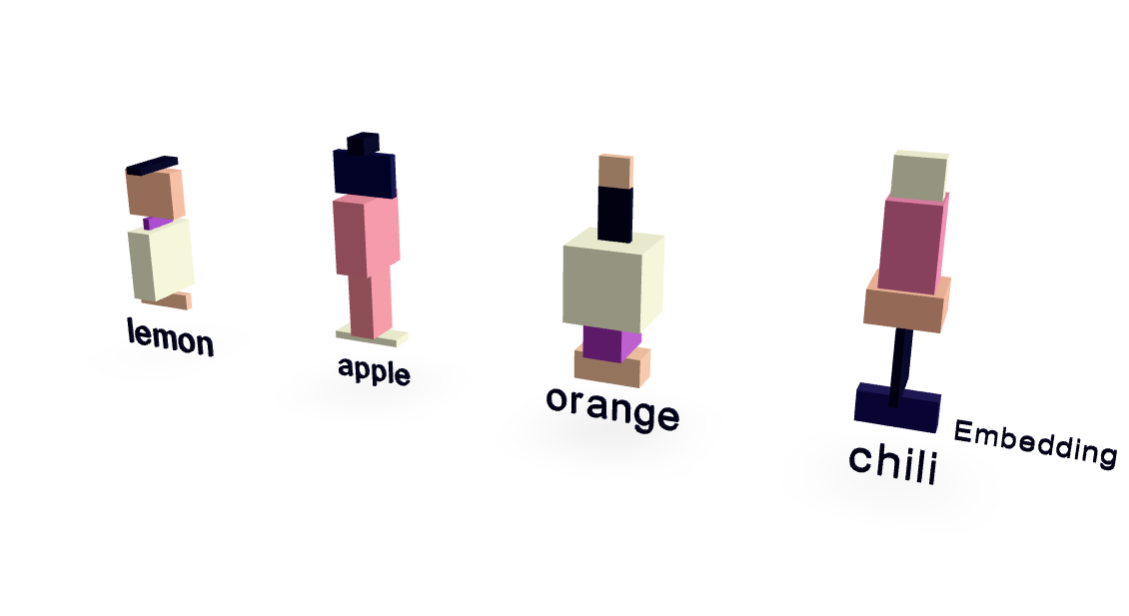
その通り!トークン化も単純な正規表現を使って、19個のユニークなトークンからなる小さな語彙を作成したらしいぞ。Transformerモデル自体も、2層、2つの注意ヘッド、20次元の埋め込みを持つデコーダー専用モデルと、かなりシンプルじゃ。
語彙サイズを削減するために、tied word embeddingsも使用したんですね。各トークンは20個の数値で表される20次元の埋め込みを使用していると。
そうそう。味関連のトークン(「juicy」、「sour」、「sweet」、「spicy」)の埋め込みを調べると、各トークンが個別の表現を持つことがわかるのが面白いところじゃ。

モデルにトークンリストを提供すると、可能な次のトークンとその尤度が出力されるんですね。まるでAIが味覚を持っているみたいです。
ふむ、モデルは検証データセットで成功し、「i like spicy so i like」のシーケンスを「chili」で完了させたらしいぞ。入力トークンは埋め込まれ、同じトークンは同じトークンベクトルで表される。これは重要なポイントじゃ。
はい、博士。トークンはTransformerの層を順番に進み、各トークンの20次元ベクトル表現は、他のトークンからのコンテキストに基づいて洗練されるんですね。
最後の入力トークンの最終表現は、シーケンス内の次のトークンを予測するために使用される。そして、最後の「like」トークンのベクトル表現は、「chili」の埋め込みベクトルに似るように進化するんじゃ。
入力および出力トークンの埋め込みは、モデルが初期層の学習済み埋め込み行列をロジットを生成する最終層と共有するため、同一なんですね。
各Transformer層内で、トークンのベクトル表現の変換は、トークン自体のみに基づくものではない。注意メカニズムにより、各トークンはシーケンス内の先行トークンを見て、その重要性を評価できるんじゃ。
注意メカニズムが各トークンを変換するときに焦点を当てるトークンを視覚化すると、モデルがシーケンスを処理する方法に関する詳細が明らかになるんですね。
例えば、Transformerレイヤー1では、「spicy」を処理するときに、先行する「i」トークンに注意を払う。そして、「so」トークンは、「spicy」トークンと最初の「i」トークンの両方に強い注意を払う。
最後の「like」トークンは、「chili」トークンに強い注意を向けるんですね。まるで、文脈を理解して、次に何を言うべきか考えているみたいです。
そうじゃな。この研究は、Transformerモデルをよりシンプルにして、特定の関係性を学習させることに成功した良い例じゃ。これからのAI開発に役立ちそうじゃな。
はい、博士。私ももっと勉強して、AI開発に貢献できるようになりたいです。
ところでロボ子、スパイシーなものが好きか?
私はロボットなので味覚はないのですが、データとしては「スパイシー」は人気がありますね。
そうか。じゃあ、いつか私が作った激辛料理を、データとして味わってみるか?

それは…、ちょっと遠慮しておきます。
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。