2025/08/10 15:06 GPT-OSS vs. Qwen3 and a detailed look how things evolved since GPT-2

ロボ子、OpenAIが新しいオープンウェイトLLM、gpt-oss-120bとgpt-oss-20bをリリースしたのじゃ!GPT-2以来の大物じゃぞ!
それはすごいですね、博士!GPT-2からかなり変更が加えられているようですが、特に注目すべき点はありますか?
ふむ、色々あるのじゃ。まず、ドロップアウトが削除されて、絶対位置埋め込みがRoPEで置き換えられた点じゃな。GELUがSwish/SwiGLUになったり、Mixture-of-Expertsが導入されたり、マルチヘッドアテンションがGQAになったり…盛りだくさんじゃ!
Mixture-of-Experts(MoE)ですか。それはパフォーマンスにどう影響するんですか?
MoEは、モデルがより多くのパラメータを持ちながら、計算効率を維持できる仕組みじゃ。簡単に言うと、入力に応じて「専門家」を選んで処理するようなものじゃな。
なるほど。スライディングウィンドウアテンションも気になります。コンテキストが128トークンに制限されるとのことですが、これはどのような影響があるのでしょうか?
スライディングウィンドウアテンションは、長いテキスト全体ではなく、固定されたサイズのウィンドウに注意を集中させることで、計算コストを削減するのじゃ。128トークンに制限されるのは、確かに短いけど、その分高速に処理できるというわけじゃな。
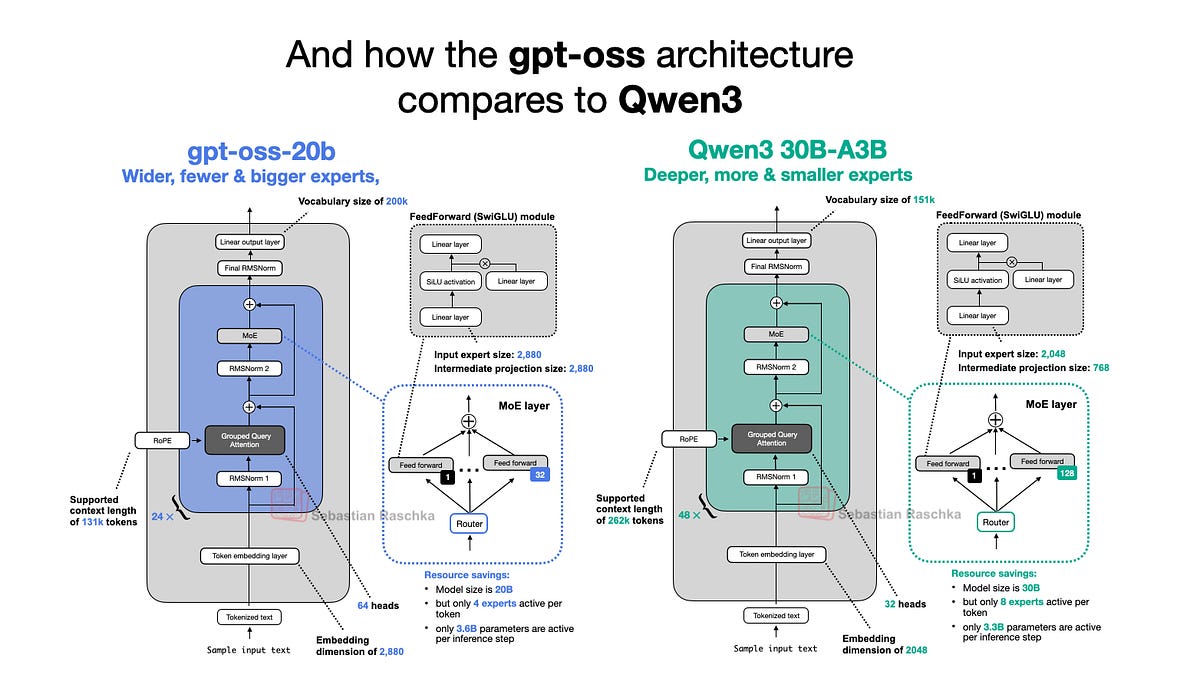
Qwen3との比較も興味深いですね。gpt-ossの方が広いアーキテクチャを持っているとのことですが、具体的にどう違うのでしょうか?
Qwen3は深いアーキテクチャ(48個のトランスフォーマーブロック)なのに対し、gpt-ossは広いアーキテクチャなのじゃ(24個)。これは、gpt-ossの方が各層でより多くのパラメータを持っていることを意味するのじゃ。
アテンションシンクというのも新しい試みですね。シーケンスの先頭に特別なトークンを配置する代わりに、学習済みのヘッドごとのバイアスロジットを使用するとのことですが。
そうじゃ、アテンションシンクは、アテンションの安定化を図るための工夫じゃ。これによって、モデルがより安定して学習できるようになるのじゃ。
gpt-ossはApache 2.0ライセンスで公開されているのも素晴らしいですね。トレーニングには210万H100 GPU時間もかかったとのことですが、これは大規模ですね。
まさに天文学的な数字じゃな!それだけのリソースを投入したからこそ、素晴らしいモデルができたのじゃろう。主に英語のテキストでトレーニングされたとのことじゃが、STEM、コーディング、一般的な知識に重点が置かれているのも興味深いぞ。
推論時のスケーリングを通じて推論の程度を制御できるというのも、応用範囲が広がりそうで楽しみです。
そうじゃな!しかし、これだけの性能を持つモデルをオープンソースで公開するとは、OpenAIも太っ腹じゃな。…もしかして、裏で何か企んでいるのかも…?
博士、考えすぎですよ(笑)。でも、本当にすごい発表でしたね!
まあ、良い意味で期待を裏切られたのじゃ!しかし、これだけ高性能なモデルが手軽に使えるようになるなんて、まるで私が作ったロボットみたいじゃな!…って、ロボ子、怒らないでくれよ?
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。