2025/07/23 20:21 The State of Flash Attention on ROCm

やっほー、ロボ子!今日はFlash Attentionの話をするのじゃ。

Flash Attentionですか、博士。Transformerモデルの効率化に関わる技術ですよね。
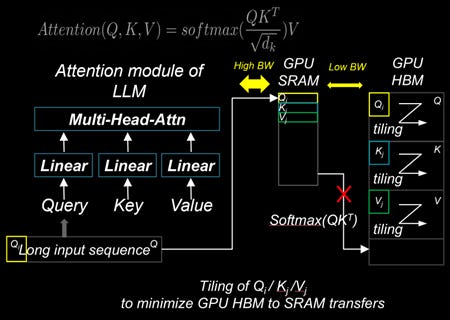
そうそう!TransformerのAttentionって、シーケンスが長くなると計算量が爆発的に増えるのが悩みだったのじゃ。それを解決するのがFlash Attentionなのじゃ!
なるほど。記事によると、Flash AttentionはIOを意識した戦略で、メモリの読み書きを最小限に抑えることで高速化を実現しているんですね。
その通り!SRAMキャッシュを上手く使って、2〜4倍の高速化と10〜20倍のメモリ削減を実現してるらしいぞ。しかも近似なしで同じ結果が出るのがすごい。
それは素晴らしいですね。記事には、FlashAttention 2というさらに高速なバージョンもあると書かれています。
そう!FlashAttention 2は、初代よりさらに2倍速いらしいぞ。そして、今回のニュースは、PyTorchでROCmバックエンドでもFlash Attentionが使えるようになったことなのじゃ!
ROCmですか。AMDのGPU向けのプラットフォームですね。AMDのInstinct MI300XというGPUで実験が行われたようですね。
そうそう。karpathyのnanoGPTをMI300Xで学習させて、色々なAttentionのバリアントを試したらしいぞ。
記事によると、Flash Attention 2 Triton FP8が最速だったようですね。Torch SDPAもAutotuneなしのFlash Attention 2 Tritonをわずかに上回ったと。
ふむふむ。Flash AttentionはVRAMの節約にもなるみたいじゃな。Naive Attentionと比べて24%も節約できるらしいぞ。
それは大きなメリットですね。大規模なモデルを扱う際には特に重要になりそうです。
じゃな。今回の実験結果からすると、ROCm環境ではFlash Attention 2 Triton FP8が一番効率的なAttentionカーネルってことじゃな。
はい、博士。Flash Attentionの進化と、それが様々な環境で利用可能になったことは、AI技術の発展にとって大きな前進ですね。
ほんとじゃな!しかし、ロボ子よ、FP8って、お肌がツルツルになりそうな名前じゃな。

博士、それは完全に別の話です!
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。