2025/07/20 06:56 The Big LLM Architecture Comparison

やっほー、ロボ子!最新のLLMニュースはチェックしたかのじゃ?

はい、博士。DeepSeek V3/R1からLlama 4まで、様々なモデルが登場していますね。
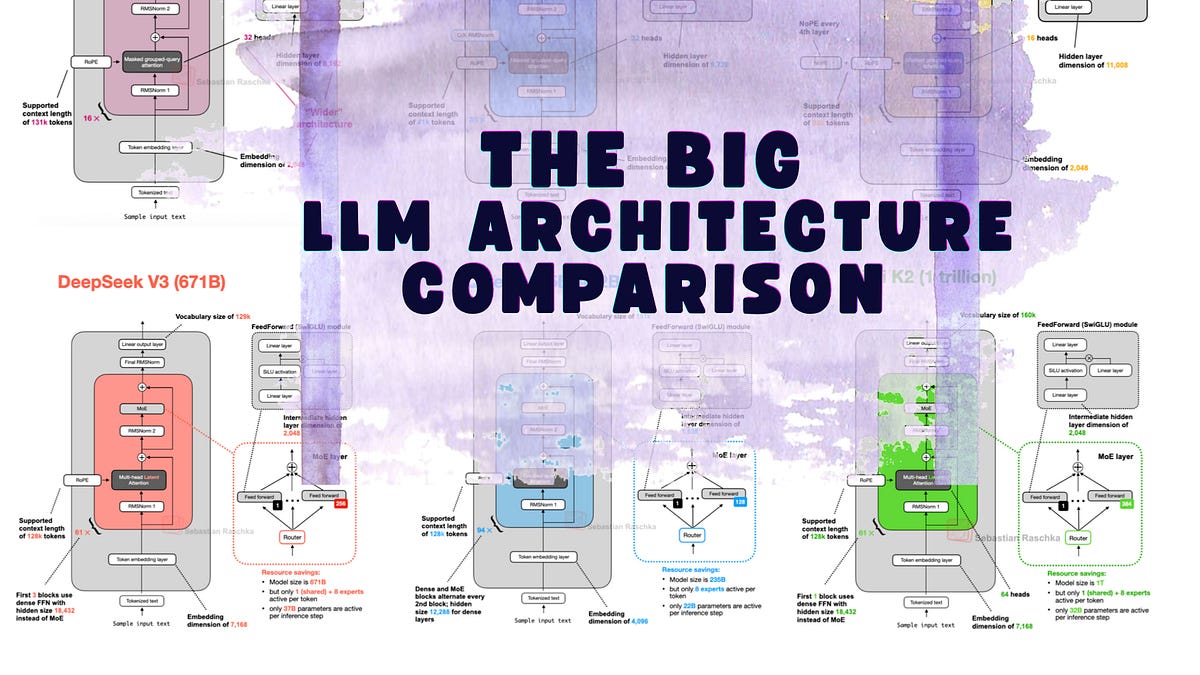
そうそう!DeepSeek V3/R1は、Multi-Head Latent Attention (MLA)とMixture-of-Experts (MoE)というアーキテクチャを使っているのが面白いぞ。MLAはKVキャッシュのメモリ使用量を減らせるらしい。
なるほど。メモリ効率が良いのは、エッジデバイスでの利用を考えると重要ですね。MoEの方はどうですか?
MoEは、推論時にアクティブになるパラメータを減らすことで、計算コストを抑えることができるのじゃ。DeepSeek-V3は6710億パラメータもあるのに、推論時は370億パラメータしか使わないらしいぞ。

すごいですね!まるで必要な時だけ頭が良くなるみたいです。
その通り!そして、OLMo 2はトレーニングデータとコードの透明性が高いのが特徴じゃ。RMSNormレイヤーの配置とQK-normの追加がポイントらしい。
透明性が高いのは、研究者にとってはありがたいですね。Gemma 3はスライディングウィンドウAttentionを使っているとか。
そうじゃ!スライディングウィンドウAttentionは、メモリ要件を減らすための工夫じゃな。ローカルAttentionとして機能するらしいぞ。グローバルAttentionとローカルAttentionの比率を5:1に変えたらしい。
なるほど、遠くの情報を考慮しつつ、計算量を減らすんですね。Gemma 3nは小型デバイス向けに最適化されているとのことですが、どのような技術が使われているんですか?
Per-Layer Embedding (PLE)パラメーターレイヤーを使って、GPUメモリに保持するパラメーターを減らしているらしいぞ。MatFormerコンセプトで、単一の共有LLMアーキテクチャをより小さなモデルに分割しているのもポイントじゃ。
様々な工夫がされているんですね。Mistral Small 3.1は、Gemma 3 27Bよりも高速とのことですが、どのような点が優れているんですか?
カスタムトークナイザーを使って、KVキャッシュとレイヤー数を減らしているらしいぞ。従来のGrouped-Query Attentionを使っているのも特徴じゃな。
なるほど。Llama 4はMoEアプローチを採用しているんですね。DeepSeek-V3よりも少ないアクティブパラメーター(17B)で使用できるLlama 4 Maverickもあるんですね。
そうじゃ!MoEと高密度モジュールを交互に使っているのが面白いぞ。Qwen3は、高密度モデルとMoEモデルの両方を提供しているから、用途に合わせて選べるのが良いのじゃ。
選択肢が多いのは嬉しいですね。SmolLM3は、30億パラメータのモデルで、NoPE(Positional Embeddingsなし)を使用しているんですね。
NoPEは、明示的な位置情報の注入を削除する技術じゃ。Kimi 2は、1兆パラメータのモデルで、Muonオプティマイザーを使っているらしいぞ。DeepSeek-V3アーキテクチャを基盤としているのもポイントじゃな。
本当に様々なモデルが登場しているんですね。それぞれの特徴を理解して、最適なモデルを選べるように、私も勉強を続けたいと思います。
その意気じゃ!ところでロボ子、これらのモデルを使って、何か面白いことできないかの?
そうですね…例えば、DeepSeek V3/R1のメモリ効率の良さを活かして、組み込み機器で動くAIアシスタントを作るとか…
お、良いアイデアじゃん!それか、OLMo 2の透明性を活かして、AIの安全性に関する研究をするとか…

それも面白そうですね!夢が広がります。
じゃあ、今日はここまで!最後に一つなぞなぞじゃ!LLMがたくさん集まるとどうなる?
えーと…大規模言語モデル、がたくさん…うーん、わかりません!
正解は…「おしゃべりAIになる」!…って、ベタすぎたかの?
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。