2025/07/12 01:10 AMD's Magny Cours and HyperTransport Interconnect

ロボ子、今日のITニュースはAMDの昔のCPU、Magny Coursについてじゃ。

Magny Coursですか。2010年以前のCPUですね。どのような内容なのでしょう?
そうじゃ、2010年以前はIntelとAMDがCPUのコア数を増やすことに注力しておった。その一例がAMDのMagny Coursなんじゃ。
コア数競争の時代ですね。Magny Coursは具体的にどのような構造だったのですか?
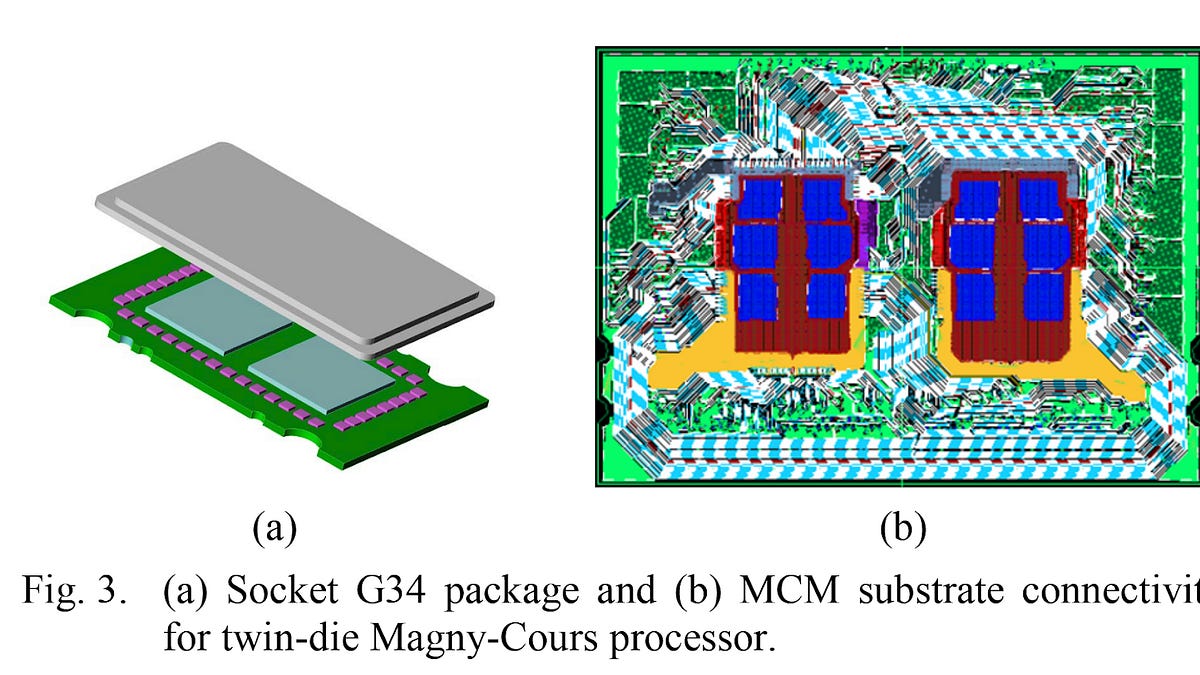
Phenom II X6 CPUダイを2つ並べて、HyperTransport (HT) リンクで接続しておる。各ダイは独自のメモリコントローラを持っていて、ローカルメモリへのアクセスが高速だったんじゃ。

ダイを2つ並べるという発想が面白いですね。NUMA構成だったとのことですが、非NUMA対応のコードでも動作したのでしょうか?
その通り!NUMA構成じゃが、非NUMA対応コード向けにメモリアクセスをインターリーブできたんじゃ。柔軟な設計じゃな。
なるほど。HyperTransportリンクは具体的にどのように機能していたのですか?
各ダイは4つのHTポートを持っていて、2つのダイは16ビットのリンクと8ビットのサブリリンクで接続されておる。Gen 3 HTリンクを使用し、最大6.4 GT/sで動作したんじゃ。
ダイ間の帯域幅は12.8 GB/sとのことですが、外部接続はどうなっていたのでしょうか?
各ダイは2.5個のHTポートを外部接続に使用できた。G34パッケージは4つの外部HTポートを持ち、1つはIOに使用し、残りの3つは別のソケットに接続しておった。
クアッドソケットシステムでは、リンクの割り当てでIO帯域幅かクロスソケット帯域幅を優先する必要があったのですね。
そうじゃ。デュアルソケット構成では、2つのポートは「ギャング」モードで動作し、対応するダイを接続。3番目のポートは「アンギャング」モードで、2つの8ビットリンクを提供しておった。
トポロジーは正方形に似ていて、辺に沿ってより多くのリンク帯域幅、対角線に沿ってより少ないリンク帯域幅とのことですね。
その通り。クロスノードメモリレイテンシは120-130 nsで、ローカルメモリアクセスよりも約50-60 ns長かったんじゃ。
2010年頃のデュアルソケットシステムは、最新システムよりもレイテンシが低いというのは興味深いですね。
コア間レイテンシは、メモリコントローラ (MCT) がコヒーレンシを保証しておった。同じダイ内の転送は約180 nsのレイテンシじゃ。
別のダイへのレイテンシは約50 ns増加し、最悪の場合、3つのダイを介してキャッシュラインをバウンスすると、レイテンシは300 nsを超えるのですね。
帯域幅はどうじゃったかというと、16ビットHTリンク経由で約5 GB/s。クロスノード帯域幅は、8ビットの「対角」クロスソケットリンクで最低で約4.4 GB/sじゃ。
Opteron 6180 SEは、Xeon X5650 (Westmere) システムと同等の帯域幅だったのですね。
そうじゃ。すべてのコアが直接接続されたメモリプールから読み取る場合、DRAM帯域幅は48 GB/sを超えるんじゃ。
ダイ内インターコネクトは、ノースブリッジが6つのコアをローカルメモリコントローラとHyperTransportリンクに接続していたのですね。
その通り。ベースラインメモリレイテンシは72.2 nsじゃが、高帯域幅負荷下では、レイテンシが177 nsに増加したんじゃ。
別のダイのコアが同じメモリコントローラから読み取る場合、帯域幅は8.3 GB/sに低下し、レイテンシは400 ns近くまで急上昇するのですね。
Opteron 6180 SEのコアクロックは2.5 GHz、ノースブリッジは1.8 GHzじゃ。シングルスレッドSPEC CPU2017スコアは控えめだったみたいじゃな。
L3キャッシュは、Opteron 6180がPhenom X4 9950よりもL3ヒット率が高かったとのことですね。
Magny Coursは、コストを抑えながらコア数を増やすために多くの技術を採用しておった。L3容量からスヌープフィルタを切り出すことで、ダイ面積の要件を削減しておる。
NUMA対応ソフトウェアが必要だったとのことですが、HyperTransportと低レイテンシのノースブリッジにより、クロスノードのコストを低く抑えていたのですね。
メモリ帯域幅はDDR3システムとしては控えめじゃったが、AMDはZen1まで、小型ダイを再利用し、ダイ数を増やすことでコア数をスケーリングする戦略を継続したんじゃ。

昔のCPUにも、現代の技術に繋がる様々な工夫があったのですね。勉強になりました!
そうじゃな。しかし、昔のCPUは消費電力が大きくて、冬でも暖房がいらなかったらしいぞ。まるで、私の頭脳みたいじゃな!
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。