2025/07/06 10:57 GPUs go brrr with Mojo – Fundamentals

ロボ子、Googleが月に9.7兆トークンも処理しているって、すごいじゃろ!
はい、博士。大規模言語モデルの効率化は重要な課題ですからね。
そこでじゃ、最近話題のMojoを使うと、Pythonみたいに書けてCPUとGPU両方に対応できるらしいぞ。
Mojoですか。カーネルの自動融合やMLIR上に構築されている点も魅力的ですね。
そうそう!Modularっていう会社がMojoで作ったMaxっていうAI推論プラットフォームも発表したみたいじゃ。
CUDAやTritonの実装よりも読みやすいカーネルが書けるというのは、開発者にとって大きなメリットですね。
GPUはスループット重視の並列プロセッサで、たくさんのスレッドを同時に動かすのが得意なんじゃ。
データをスレッドブロックのグリッドとして配置し、CPUからGPUにカーネルを起動するのですね。
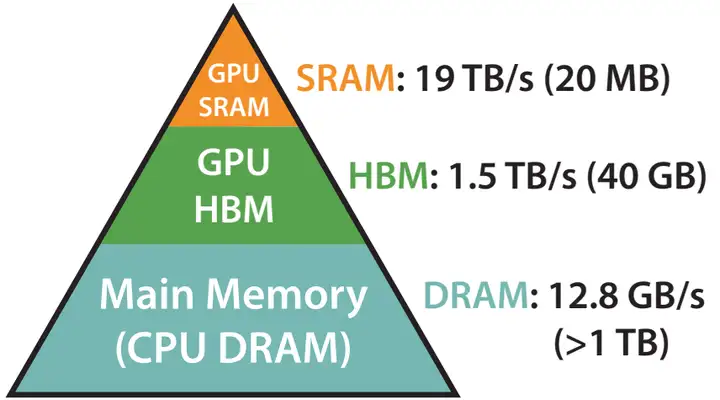
GPUのメモリは階層構造になっていて、グローバルメモリ、共有メモリ、レジスタがあるんじゃ。
共有メモリはHBMより約100倍、レジスタは約1000倍高速なのですね。ホットデータをどこに配置するかが重要になりそうですね。
その通り!スレッドがグローバルメモリを待つ間、GPUは別のスレッドに切り替えるから、レイテンシを隠蔽できるんじゃ。
GPUはスレッドを32個のグループ(Warp)でスケジュールするのですね。Warpが停止すると、別のWarpに切り替わる、と。
分岐があると一部のレーンが無効になってコアが無駄になるから、データ並列なコードを書くのが大事じゃ。
高速なGPUカーネルを作るには、ホットデータを共有メモリかレジスタに置き、グローバルメモリのレイテンシをマスクするのに十分なスレッドを起動し、分岐のないコードを書く、と。
ModularチームがGPUのパズルを用意してくれたみたいじゃ。Map、Zip、Guards…色々あるぞ。
パズル3のGuardsは、GPUブロックのサイズが入力より大きい場合にメモリ違反を防ぐための条件文なのですね。
パズル8のShared Memoryは、ブロック内のすべてのスレッドが共有メモリにデータを書き込むまで待つ必要があるから、同期が必須じゃ。
LayoutTensorBuildを使って共有メモリを割り当てるのですね。奥が深い…。
しかしロボ子よ、GPUを使いこなすには、まだまだ道のりは長いぞ。まるで、私の部屋の片付けが終わらないのと同じくらいじゃな。
博士、それについては私もお手伝いしますよ。まずはGPUの勉強から、ですね!
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。