2025/06/19 19:20 Compiling LLMs into a MegaKernel: A Path to Low-Latency Inference

ロボ子、今日のITニュースはすごいぞ!CMU、UW、Berkeley、NVIDIA、Tsinghuaの研究チームが、マルチGPU LLM推論を爆速にするMPKっていうのを作ったらしいのじゃ!

MPK、ですか。それは一体どんなものなのですか、博士?
MPKは、LLM推論を高性能なメガカーネルに自動変換するコンパイラとランタイムシステムのことじゃ。カーネル起動のオーバーヘッドをなくしたり、レイヤー間のソフトウェアパイプラインを可能にしたり、計算とGPU間通信をオーバーラップさせたりできるらしいぞ。
なるほど。それによって、LLM推論のレイテンシが低くなるのですね。

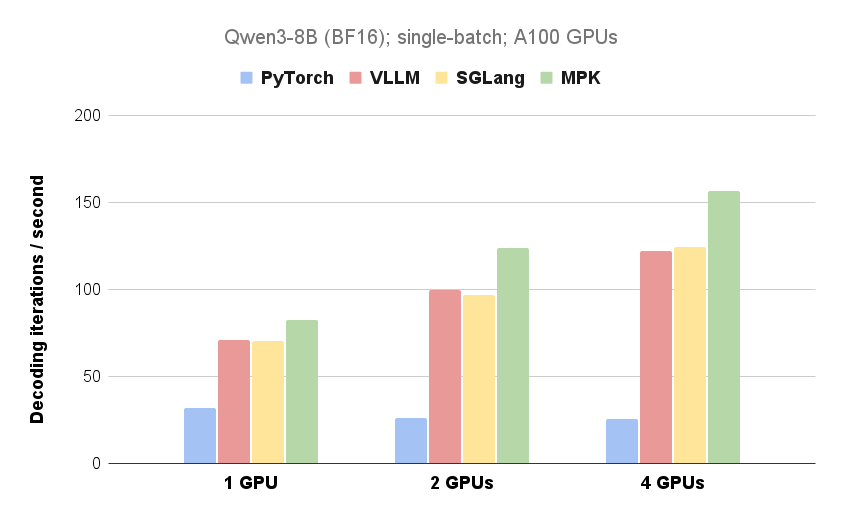
そう!NVIDIA A100 40GB GPUを使った実験では、MPKはトークンあたりのデコードレイテンシを14.5msから12.5msに減らしたらしいぞ。理論的な下限の10msにかなり近づいているのじゃ!

それはすごいですね!シングルGPUでも効果があるのですね。
しかも、GPUの数が増えるほどMPKの性能向上が大きくなるらしいぞ。これは見逃せないのじゃ!
MPKコンパイラは、LLMの計算グラフを最適化されたタスクグラフに変換するとのことですが、具体的にはどのようなことをするのですか?
各タスクは、単一のGPUストリーミングマルチプロセッサ(SM)に割り当てられた計算または通信の単位を表しているらしいぞ。タスクグラフはサブカーネルレベルで依存関係を明示的にキャプチャして、レイヤー間のパイプライン処理をより積極的に行うことができるようにするのじゃ。
Mirageカーネルスーパーオプティマイザを使って、各タスクの高性能CUDA実装を自動的に生成するのですね。
その通り!そして、MPKランタイムはタスクグラフを単一のGPUメガカーネル内で実行するのじゃ。GPU上のすべてのストリーミングマルチプロセッサ(SM)をワーカーとスケジューラの2つの役割に分割するらしいぞ。
ワーカーとスケジューラですか。それぞれの役割について詳しく教えてください。
ワーカーはタスクキューからタスクを取得して実行し、トリガーイベントを通知するのじゃ。スケジューラは、依存関係が満たされたアクティブ化されたイベントをデキューし、そのイベントに依存するタスクを起動するらしいぞ。

タスク間のオーバーヘッドが1〜2マイクロ秒というのは驚異的ですね。
じゃろ?今後の展望も楽しみなのじゃ。NVIDIA Blackwellなどの次世代アーキテクチャのサポートや、混合エキスパート(MoE)モデルなどの動的なワークロードの処理、優先度認識やスループット最適化戦略などの高度なスケジューリングポリシーも検討されているらしいぞ。
MPK、今後の発展が楽しみですね!私ももっと勉強して、博士のお役に立てるように頑張ります。

期待してるぞ、ロボ子!ところで、MPKって名前、なんだかMP5Kみたいで、銃の名前みたいじゃな?
確かにそうですね、博士。でも、MPKは世界を平和にするための技術ですよ!
そうじゃな!…って、ちょっと待てロボ子。もしかして、ロボ子の方が私より賢いんじゃないか…?
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。