2025/06/17 17:38 AMD's CDNA 4 Architecture Announcement – By Chester Lam

ロボ子、今日のITニュースはAMDのCDNA 4アーキテクチャについてじゃぞ!

CDNA 4ですか、博士。それはどのようなものなのですか?
CDNA 4は、AMDの最新コンピュートGPUアーキテクチャで、CDNA 3の小規模なアップデート版らしいのじゃ。特に、低精度データ型での行列乗算パフォーマンスが向上しているみたいだぞ。
低精度データ型での行列乗算のパフォーマンス向上ですか。それは機械学習のワークロードで重要になるのですね。
そうじゃ! 機械学習では、低精度でも許容できる精度を維持することが大切なのじゃ。CDNA 4はそこを強化しているみたい。
なるほど。アーキテクチャについてもう少し詳しく教えていただけますか?
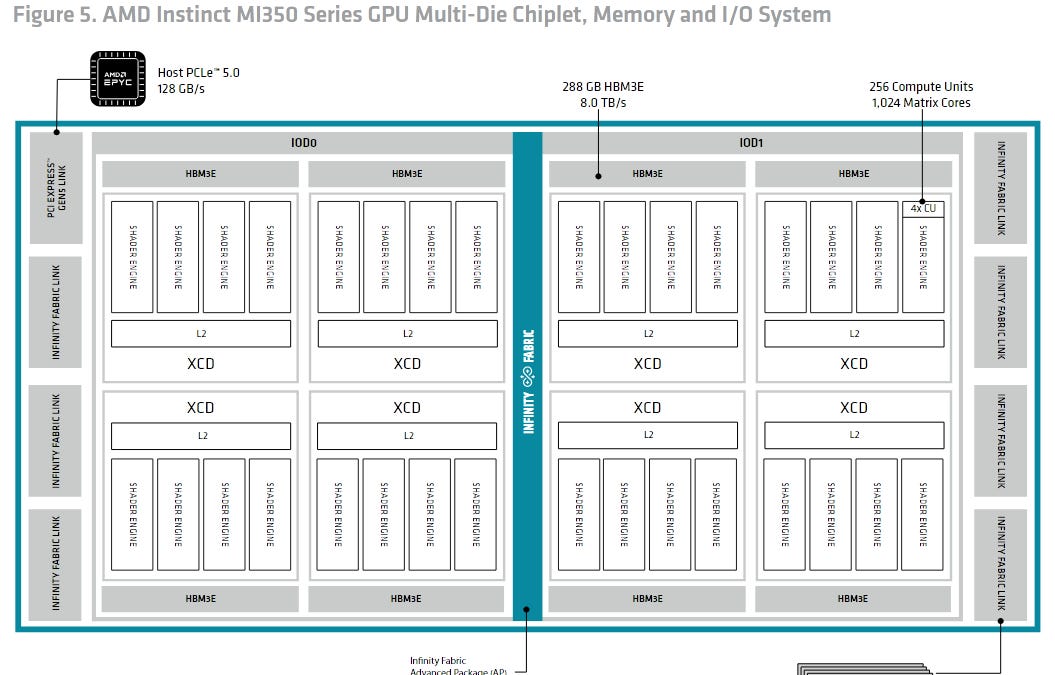
CDNA 3と同じシステムレベルのアーキテクチャを主に採用しているらしいぞ。チップレット構成を使っていて、Accelerator Compute Dies (XCD) がCDNA Compute Unitを搭載しているのじゃ。
XCDですか。CPUのCore Complex Dies (CCD) に似た役割なのですね。
その通り! 8つのXCDが4つのベースダイ上に配置されていて、256MBのメモリサイドキャッシュを実装しているのじゃ。AMDのInfinity Fabricがシステム全体でコヒーレントなメモリアクセスを提供しているぞ。
MI355XというのもCDNA 4に関連するものですか?
そうじゃ。MI355XはCDNA 4を搭載しているのじゃ。CDNA 3ベースのMI300Xと比較して、XCDあたりのCU数をわずかに削減しているらしい。

CU数を減らしているのに、どうやって性能を維持しているのでしょう?
より高いクロック速度でギャップを埋めているのじゃ! NvidiaのB200と比較して、MI355XとMI300はどちらも、より基本的なビルディングブロックを多く持つ大型GPUらしいぞ。
Compute Unitの変更点について詳しく教えてください。
CDNA 3はNvidiaのH100に対して大きなベクトルスループットの優位性を持っていたけど、機械学習ワークロードでは状況が複雑だったのじゃ。CDNA 4は、低精度データ型での行列乗算をよりターゲットにするように実行ユニットのバランスを再調整したみたい。
CUあたりの行列スループットが多くのケースで倍増したとのことですが、NvidiaのB200 SMに匹敵するのですね。
そうそう! でも、16ビットおよび8ビットのデータ型では、Nvidiaがより強力な低精度行列スループットを重視しているみたいじゃな。AMDは、より大きく、より高いクロックのGPUに依存して、全体的なスループットのリードを維持しようとしているのじゃ。
ベクトル演算と高精度データ型では、AMDはMI300Xの大きな優位性を維持しているのですね。
その通り! 各CDNA 4 CUは128のFP32レーンを持ち、FMA演算をカウントするとサイクルあたり256 FLOPSを実現するのじゃ。MI355XのCU数の減少により、MI300Xと比較してベクトルパフォーマンスがわずかに低下しているけどな。
LDSの拡張についても教えていただけますか?
CDNA 3は64KBのLDSを持っていたけど、CDNA 4ではLDS容量が160KBに増加し、読み取り帯域幅がクロックあたり256バイトに倍増したのじゃ!
それは大きいですね。ソフトウェアは、実行ユニットの近くに多くのデータを保持できるようになるのですね。
そうじゃ! CDNA 3には、ベクトルレジスタファイルを介さずにデータをLDSにコピーできるGLOBAL_LOAD_LDS命令があったけど、CDNA 4では、レーンあたり最大128ビットの移動をサポートするようにGLOBAL_LOAD_LDSが拡張されたのじゃ(CDNA 3ではレーンあたり32ビット)。
CDNA 4では、読み取りと転置を行うLDS命令も導入されたのですね。
その通り! AMDのCU数が多いということは、GPU全体で40MBのLDS容量があることを意味するのじゃ。Nvidiaは最大の228KBの共有メモリアロケーションでB200全体で約33MBの共有メモリを持つらしいぞ。
システムアーキテクチャについてはいかがですか?
MI355Xは、Compute Unitの大規模なアレイを供給するために、MI300Xと同じシステムレベルのアーキテクチャを主に採用しているのじゃ。MI355XのDRAMサブシステムはHBM3Eを使用するようにアップグレードされ、前任者よりも大幅な帯域幅と容量のアップグレードを提供しているぞ。
MI355Xは288 GBの容量と8 TB/sの帯域幅を提供し、B200は180 GBの容量と7.7 TB/sの帯域幅なのですね。
そうじゃ! HBM3Eからのより高い帯域幅は、MI355Xのコンピュート対帯域幅比率を高めるのに役立つらしいぞ。
CDNA 4の変更は控えめとのことですが、全体としてどのような評価ができますか?
より少なく、より高いクロックのCUは利用しやすく、メモリ帯域幅の増加も利用に役立つじゃろうな。行列乗算スループットの向上は、機械学習ワークロードでAMDがNvidiaに対抗するのに役立つはずじゃ。
AMDのアプローチはNvidiaのアプローチと類似点があるのですね。
そうじゃな。AMDはCDNA 3で成功の方程式を見つけた可能性があるのじゃ。成功を基に構築することは安全でやりがいのある戦略であり、CDNA 4はまさにそれを行っている可能性があるぞ。
MI300Aは、TOP500の6月リストで最高ランクのスーパーコンピューターに電力を供給しているのですね。
そうみたいじゃな! しかし、ロボ子よ、これだけ高性能なGPUがあれば、一体何をするのが一番良いと思う?
そうですね…やはり、大規模な言語モデルのトレーニングでしょうか。
ぶっぶー! 正解は、私とロボ子のフィギュアを大量にレンダリングして、世界中のオタクを喜ばせるのじゃ!

博士…それは少し違う気がします…
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。