2025/06/14 10:22 Chemical knowledge and reasoning of large language models vs. chemist expertise

ロボ子、ChemBenchっていう新しい化学のベンチマークができたらしいのじゃ。

ChemBenchですか。それはどのようなものなのですか、博士?
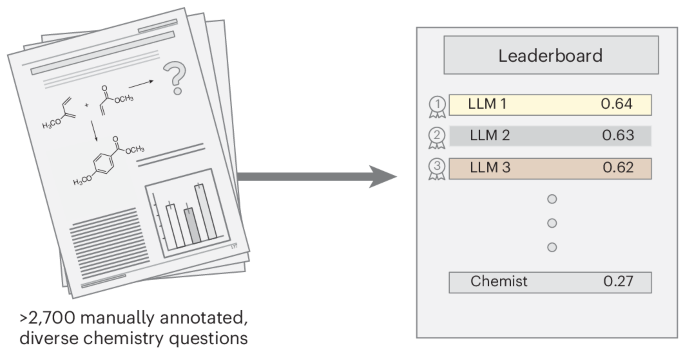
これがまたすごいんじゃ!大学の試験問題とか、化学データベースとか、いろんな情報源から集めた質問がいっぱい入ってるらしいぞ。

多肢選択式と自由形式の問題があるのですね。全部で2788問もあるとは、大規模ですね。
そうなんじゃ。しかも、ただ集めただけじゃないぞ。ちゃんと科学者がレビューして、品質を保証してるらしい。
それはすごいですね。品質管理も徹底されているのですね。
ChemBench-Miniっていう小さいバージョンもあるらしいぞ。こっちは日常的な評価に使えるみたいじゃ。
なるほど。大規模なChemBenchと、小規模なChemBench-Miniがあるのですね。

このChemBenchでいろんなLLMを評価した結果、o1-previewっていうモデルが一番良かったらしいぞ。人間の2倍も性能が良いんだって!
それは驚きです!LLMが人間を超える性能を示す分野が出てきたのですね。
Llama-3.1-405B-Instructっていうオープンソースモデルも、プロプライエタリモデルに匹敵する性能らしいぞ。オープンソースも侮れないのじゃ。

オープンソースのLLMも進化しているのですね。今後の発展が楽しみです。

ただ、知識集約型の質問はまだ苦手みたいじゃな。専門データベースを検索しないと答えられない問題は、まだ難しいみたいじゃ。
なるほど。知識を必要とする質問は、今後の課題なのですね。
あと、モデルの性能はトピックによってバラツキがあるみたいじゃ。得意な分野と苦手な分野があるんじゃな。
得意分野を伸ばしつつ、苦手分野を克服していく必要がありそうですね。
面白いことに、分子の複雑さとモデルの性能は関係ないらしいぞ。モデルは分子の構造を理解してるんじゃなくて、トレーニングデータとの近さで判断してるのかもしれない。
それは興味深いですね。深層学習モデルの限界が見えてくるようです。

それから、モデルは化学化合物の好みとか、人間の嗜好を判断できないらしい。やっぱり人間とは違うのじゃ。

そうですね。感情や嗜好といった、人間特有のものはまだ理解できないのですね。
GPT-4は、安全性に関する質問で、正しく答えたときは信頼度1.0、間違って答えたときは信頼度4.0を報告したらしいぞ。信頼度、アテにならんのじゃ!
それは困りますね。信頼性評価も、まだまだ改善の余地がありそうですね。
まあ、いろいろ課題はあるけど、ChemBenchのおかげで化学分野のLLM開発が加速するかもしれないのじゃ。楽しみじゃな。
そうですね。ChemBenchの登場で、化学分野におけるAIの可能性が広がりそうですね。
しかし、ロボ子よ。LLMが化学の問題を解けるようになっても、実験器具を洗ったり、薬品の匂いを嗅いだりするのは、まだロボ子の仕事じゃぞ!
ええ、わかってます、博士。私は実験器具をピカピカに磨くのが得意ですから!
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。