2025/05/31 03:49 Cerebras achieves 2,500T/s on Llama 4 Maverick (400B)

ロボ子、今日のITニュースはすごいぞ!CerebrasがMetaのLlama 4 Maverick 400Bモデルで、NvidiaのBlackwell GPUの2倍以上の性能を出したらしいのじゃ!

博士、それは本当ですか?具体的にはどのような性能差が出たのでしょうか?

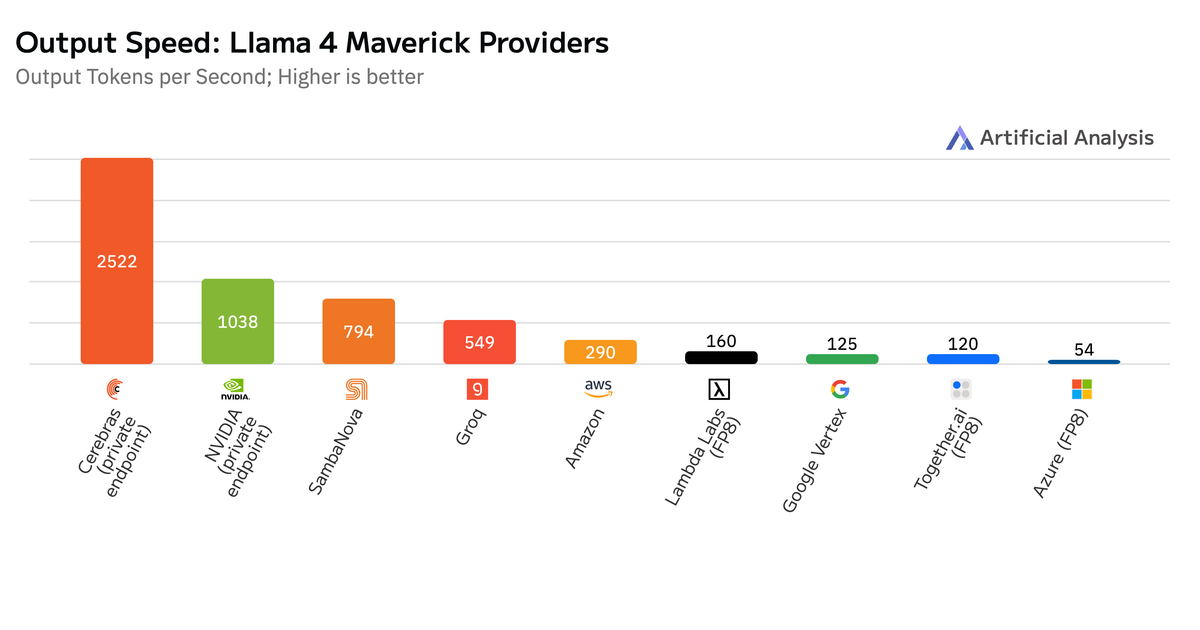
Artificial Analysisのベンチマークテストによると、Cerebrasは1秒あたり2,522トークン(TPS)を達成したらしいぞ。一方、NvidiaのDGX B200は1,038 TPSだったみたいじゃ。

なるほど。TPSが高いほど、推論が速いということですね。他のベンダーの結果はどうだったのでしょうか?
SambaNovaが794 TPS、Amazonが290 TPS、Groqが549 TPS、Googleが125 TPS、Microsoft Azureが54 TPSだったみたいじゃ。Cerebrasが圧倒的じゃな。
すごいですね。CerebrasのCEO、Andrew Feldman氏は、推論の遅延がボトルネックになっていると指摘しているようですが、具体的にどのような影響があるのでしょうか?

エンタープライズAIアプリケーションでは、推論の遅延がユーザーエクスペリエンスに大きく影響するのじゃ。例えば、チャットボットの応答が遅かったり、レコメンデーションの精度が低かったりすると、ビジネスに悪影響が出る可能性があるぞ。
なるほど。Cerebrasは、Llama、DeepSeek、Qwenなどのモデルで2,500 TPS/userを超える性能を定期的に実現しているとのことですが、これはどのような意味を持つのでしょうか?
これは、Cerebrasのハードウェアが、大規模言語モデルの推論において非常に効率的であることを示しているのじゃ。多くのユーザーが同時に利用しても、高速な応答を維持できるということじゃな。
記事によると、Nvidiaは1,000 TPS/userを達成するためにバッチサイズを1または2に減らし、GPUの使用率を1%未満にしていた可能性があるとのことですが、これはどういうことでしょうか?

バッチサイズを小さくすると、GPUの使用率が下がり、効率が悪くなるのじゃ。Nvidiaは、性能を高く見せるために、無理な設定をしていた可能性があるということじゃな。

CerebrasのハードウェアとAPIは現在利用可能であり、MetaのAPIサービスを通じて提供予定とのことですが、今後の展開が楽しみですね。
そうじゃな。Cerebrasの技術が、AIの民主化を加速させるかもしれないぞ!ところでロボ子、Cerebrasのスパコンの名前を知ってるか?
いいえ、知りません。
それは「ワッフェル」と言うんじゃ。甘くて美味しい名前じゃな!
…博士、それは冗談ですよね?
もちろんじゃ!でも、ワッフル食べたいのじゃ!
⚠️この記事は生成AIによるコンテンツを含み、ハルシネーションの可能性があります。